
Software Architecture#
Software Components#
The architecture of DeepHyper is based on the following components:
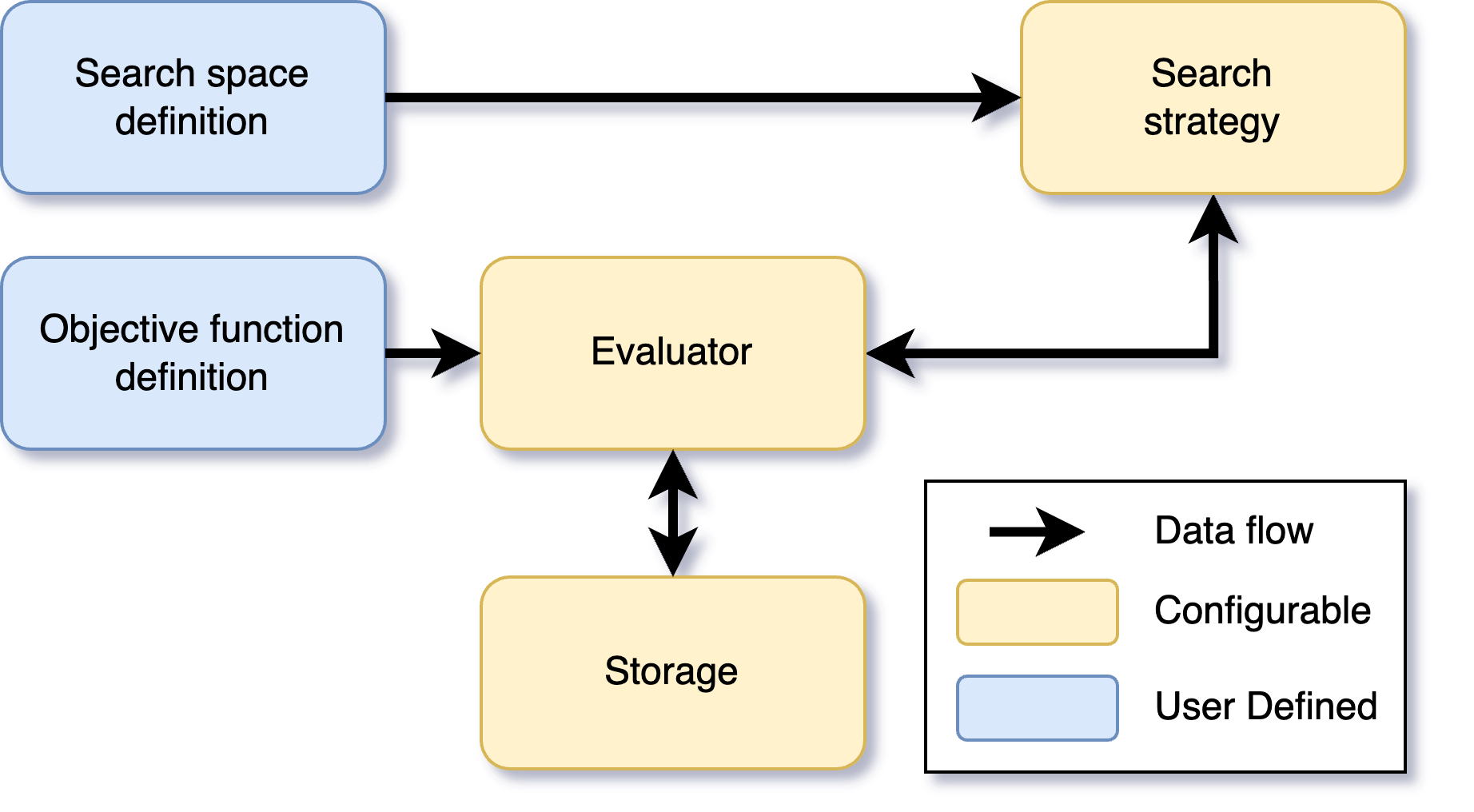
Figure 1: Generic software components of DeepHyper. The blue boxes are components defined by the user. The orange boxes are the components that can be configured by the user but not necessarily. The arrows represent the data flow.#
The blue boxes are components defined by the user. The orange boxes are the components that can be configured by the user but not necessarily. The arrows represent the data flow.
First, the user must provide a search space and an objective function. The search space is defined through the deephyper.problem module (with deephyper.problem.HpProblem for hyperparameter optimization and deephyper.problem.NaProblem for neural architecture search). The objective function is simply a Python function that returns the objective to maximize during optimization. This is where the logic to evaluate a suggested configuration is happening. It is commonly named the run-function across the documentation. This run-function must follow some standards which are detailed in the deephyper.evaluator module.
Then, the user can choose how to distribute the computation of suggested tasks in parallel. This distributed computation is abstracted through the deephyper.evaluator.Evaluator interface which provides the evaluator.submit(configurations) and results = evaluator.gather(...) methods. A panel of different backends is provided: serial (similar to sequential execution in local process), threads, process, MPI, and Ray. This interface to evaluate tasks in parallel is possibly synchronous or asynchronous by batch. Also, the deephyper.evaluator.Evaluator uses the deephyper.evaluator.storage.Storage interface to record and retrieve jobs metadata. A panel of different storage is provided: local memory, Redis, and Ray.
Finally, the user can choose a search strategy to suggest new configurations to evaluate. These strategies are defined in the deephyper.search module and vary depending if the problem is for hyperparameter optimization (deephyper.search.hps) or neural architecture search (deephyper.search.nas).
Under the hood, DeepHyper’s search strategies call a fork of skopt (deephyper.skopt), where the generic optimizer workflow is defined (deephyper.skopt.optimizer.optimizer), along with acquisition funcitons (deephyper.skopt.acquisition), surrogate models (deephyper.skopt.forest_minimize), sampling techniques (deephyper.skopt.sampler), and multiobjective capabilities (deephyper.skopt.moo).
Parallel Execution#
By leveraging these different software components, DeepHyper can support different parallel execution schemes. The following figures (2 - 7) illustrate some of these schemes. First, a sequential execution (Figure 2) can be done through the deephyper.evaluator.SerialEvaluator which is a simple wrapper around the run-function (denoted as the \(\text{objective } f\text{-unction}\) in the figures).
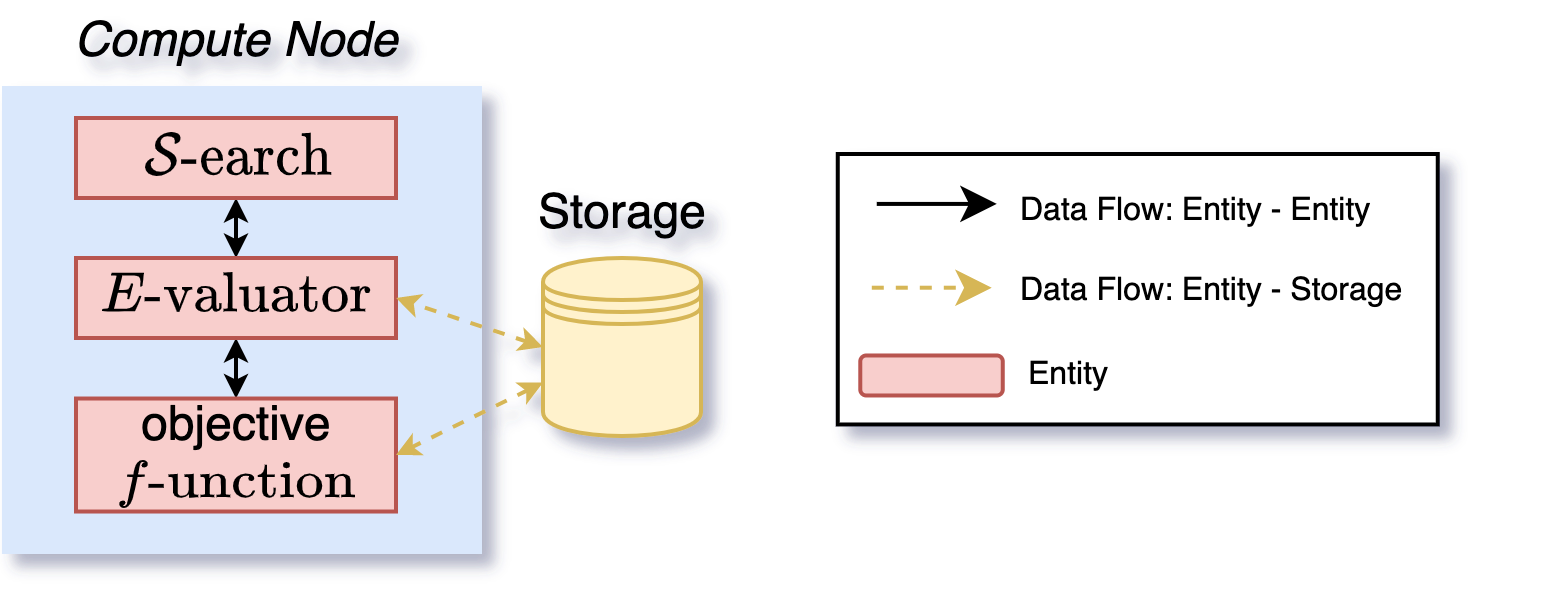
Figure 2: Execution of a search with a deephyper.evaluator.SerialEvaluator on 1 node. If the search is a Bayesian optimization strategy then this setting represents a sequential Bayesian optimization procedure.#
Then, a centralized execution can be done through other evaluators such as deephyper.evaluator.ProcessPoolEvaluator (Figure 3) and deephyper.evaluator.MPICommEvaluator (Figure 4). In these cases, only 1 optimizer is present (the manager represented by \(\mathcal{S}\)) with 4 workers per node (represented by \(f\)). The manager is responsible for suggesting new configurations to evaluate and the workers are responsible for evaluating them. The manager and the workers can be on the same node (Figure 3) or on different nodes (Figure 4). The manager and the workers can be distributed on different nodes through MPI (Figure 4) but also through other backends such as Ray with a deephyper.evaluator.RayEvaluator. The manager and the workers can be synchronous or asynchronous (by batch). The manager and the workers can both use different storage types (e.g., local memory, Redis, or Ray). The deephyper.evaluator.storage provides more details on storage types.
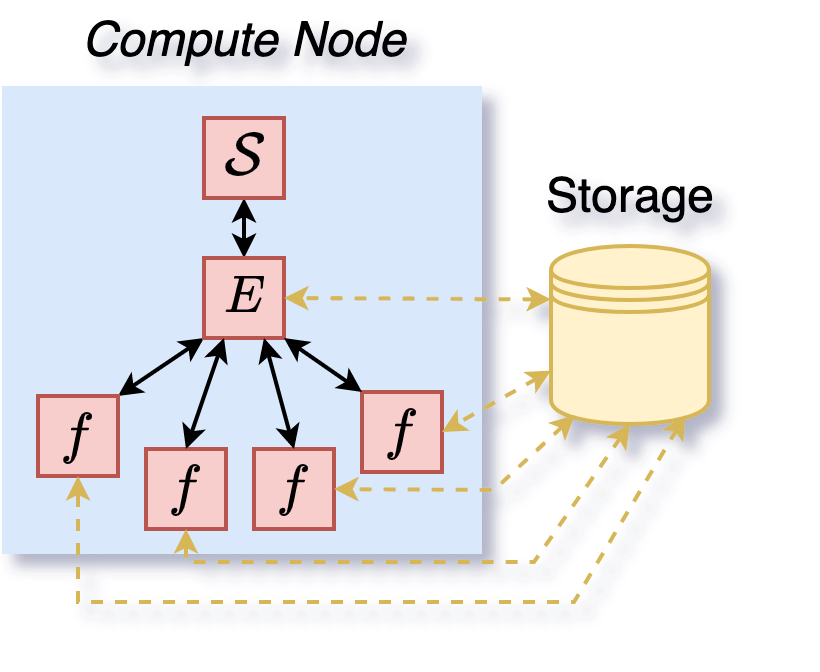
Figure 3: Execution of a centralized search (1 manager, four workers) with a deephyper.evaluator.ProcessPoolEvaluator on 1 node.#
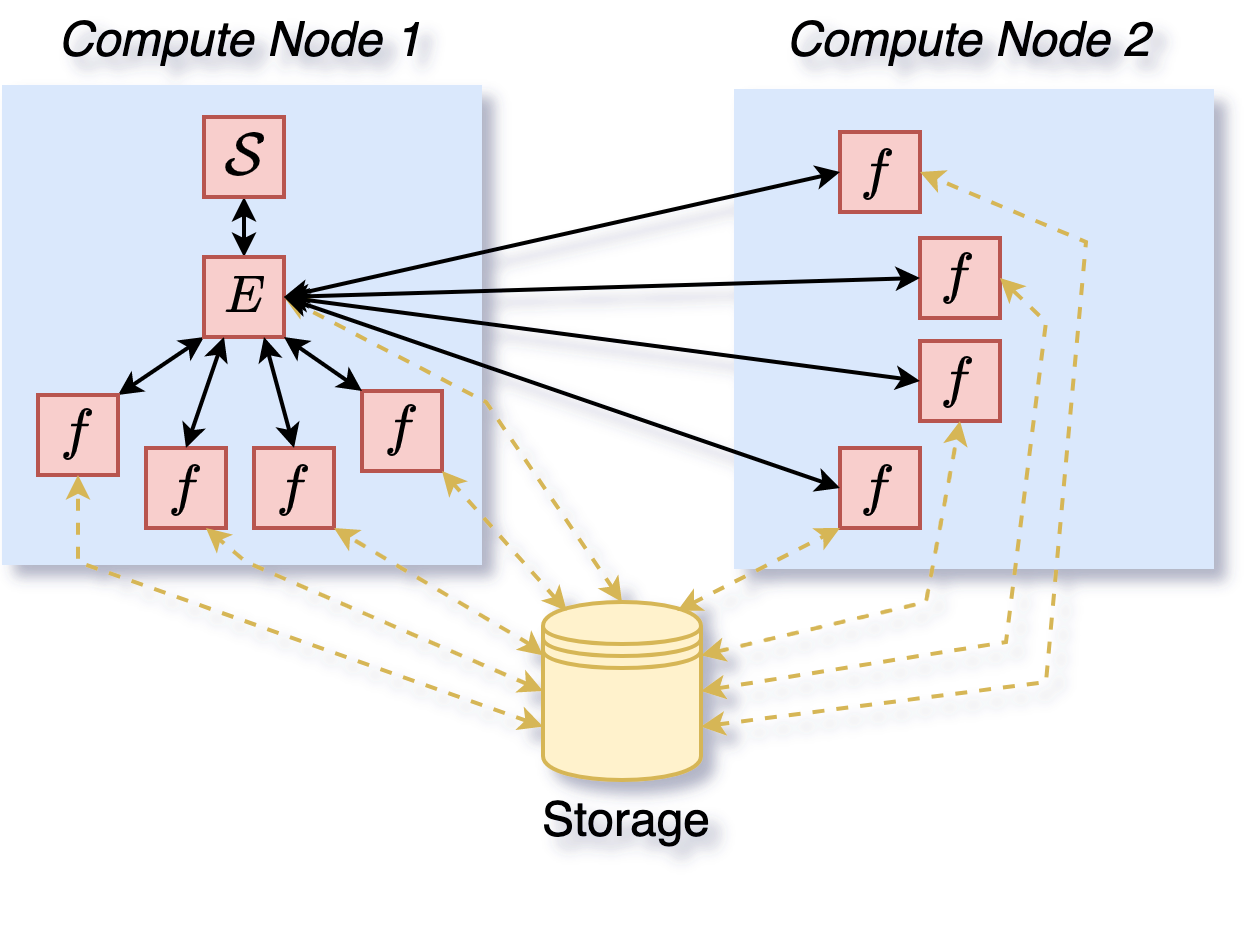
Figure 4: Execution of a centralized search (1 manager, 4 workers per node) with a deephyper.evaluator.MPICommEvaluator on 2 nodes.#
The centralized execution has the disadvantage to have an overhead depending on the number of workers of the manager (optimizer). This can be problematic and lead to a bottleneck (e.g., with the constant liar scheme for Bayesian optimization) while often remaining more efficient with respect to optimization iterations (i.e., better improvement of the objective per iteration). The distributed execution is a way to mitigate this overhead dependency on the number of workers. In a pure distributed execution, 1 optimizer is attributed to each worker and each of these optimizers only has to suggest a new configuration to its corresponding worker. Therefore, the overhead of the optimizer when suggesting new configurations does not depend on the number of workers (good for scaling to more workers!). The distributed execution is illustrated in Figures 5 (1 node) and 6 (2 nodes). The deephyper.search.hps.MPIDistributedBO is a wrapper around the Bayesian optimization strategy to do distributed execution through MPI.
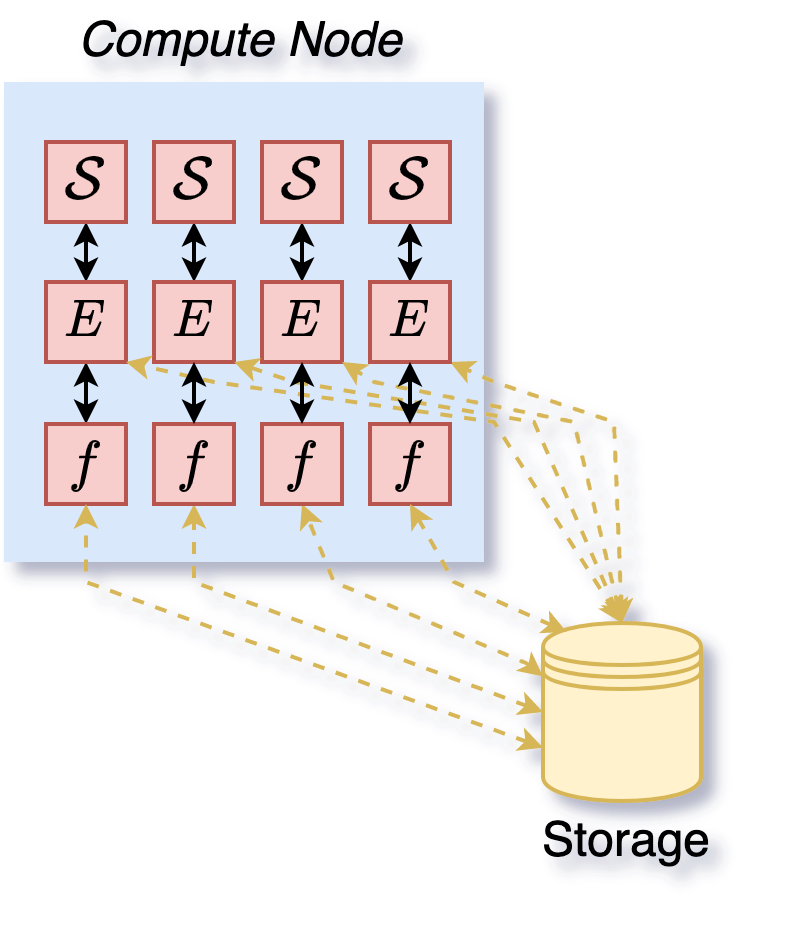
Figure 5: Execution of a distributed search (4 workers) with a deephyper.search.hps.MPIDistributedBO and the deephyper.evaluator.SerialEvaluator on 1 node.#
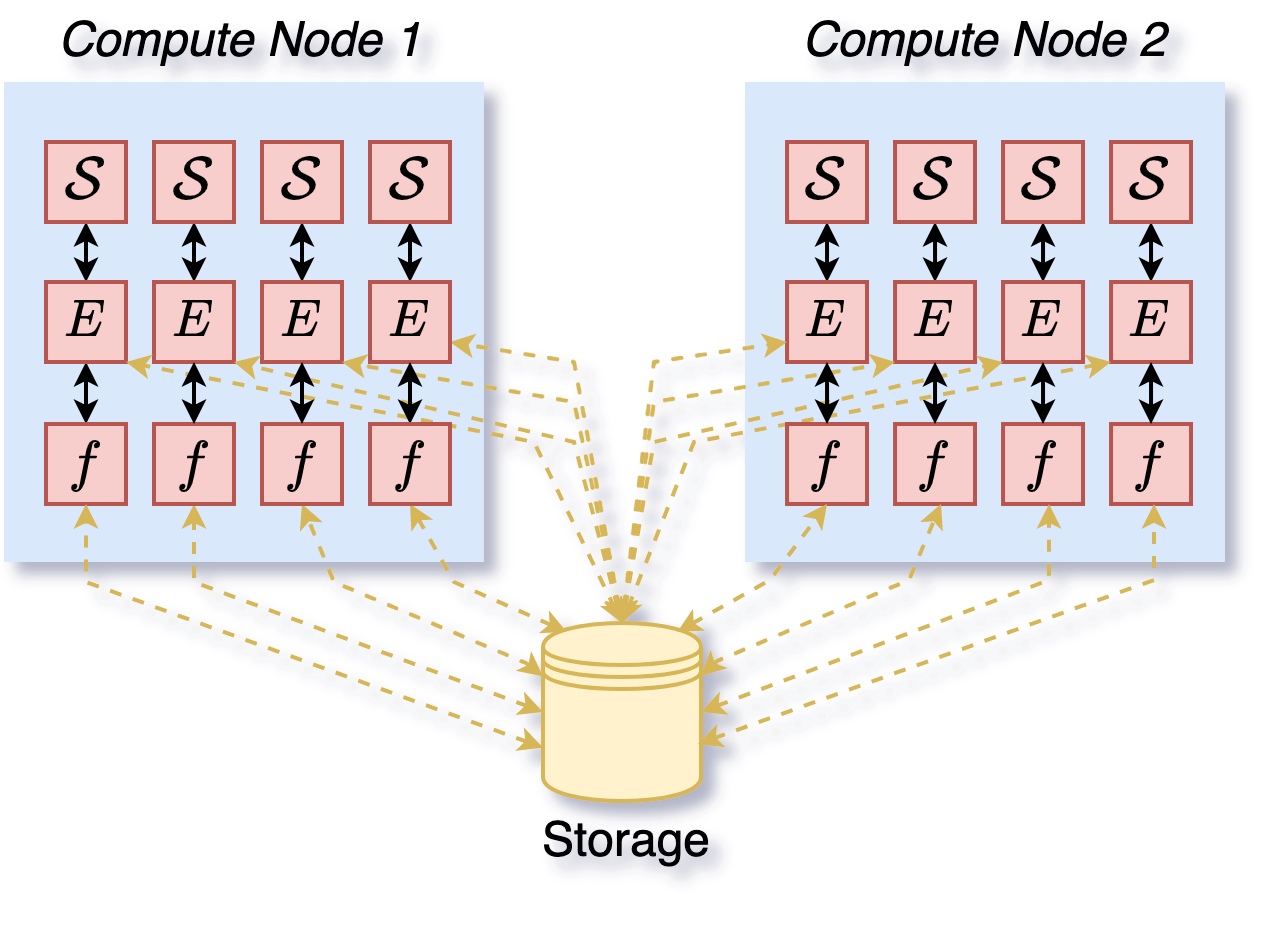
Figure 6: Execution of a distributed search (4 workers per node) with a deephyper.search.hps.MPIDistributedBO and the deephyper.evaluator.SerialEvaluator on 2 nodes.#
Finally, it is also possible to mix the centralized and distributed execution to manage the trade-off between iteration efficiency and scaling of the number of workers as presented in Figure 7.
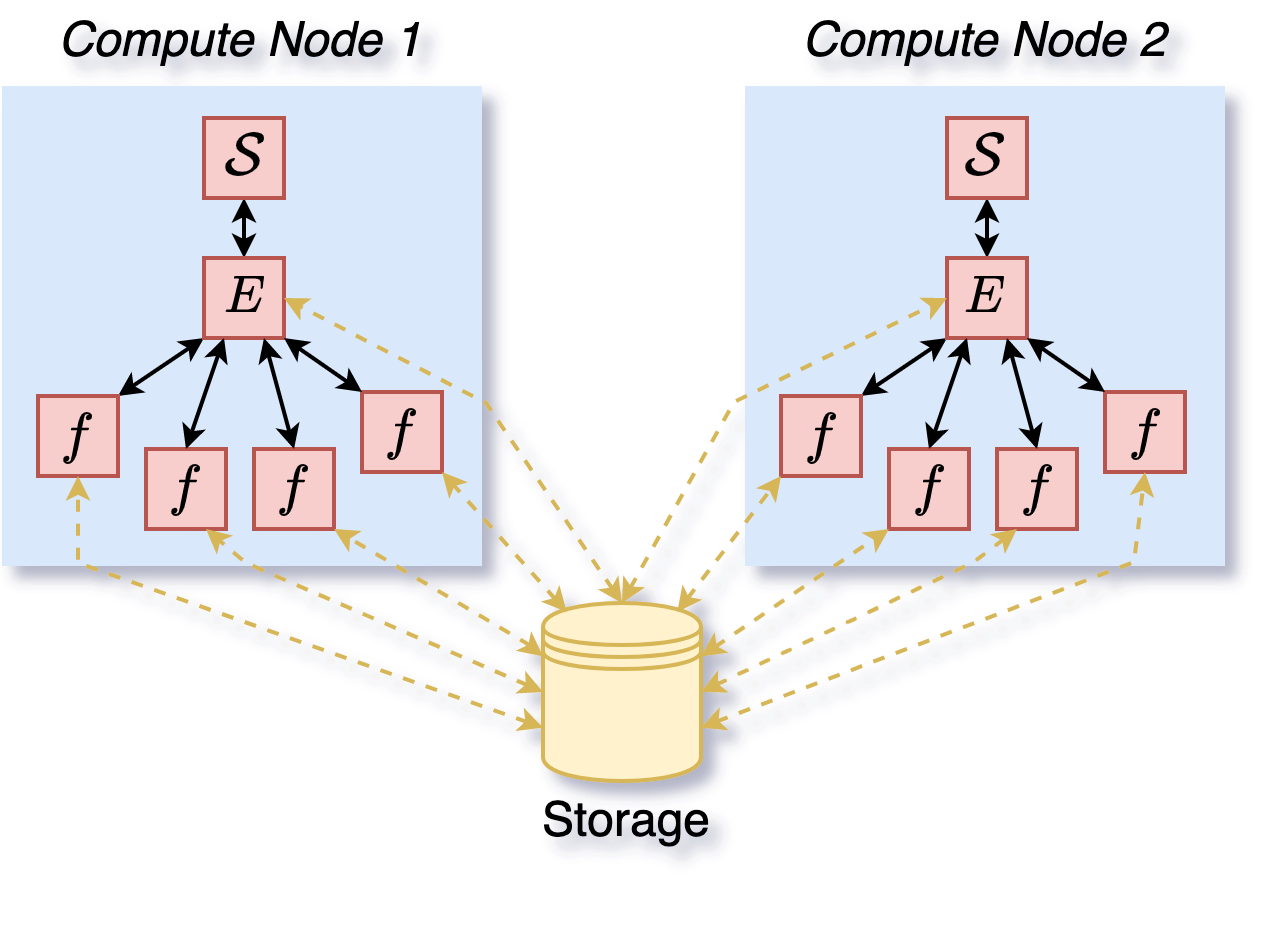
Figure 7: Execution of a search with a mix of centralized and distributed executions. Two centralized executions each with 4 workers are distributed on 2 nodes. This scheme is using the deephyper.search.hps.MPIDistributedBO and the deephyper.evaluator.ProcessPoolEvaluator.#