
Neural Architecture Search for LSTM Neural Networks#
Warning
Be sure to work in a virtual environment where you can easily pip install new packages. This typically entails using either Anaconda, virtualenv, or Pipenv.
In this tutorial example, we wil recreate results from our recent paper on LSTM search for surrogate modeling of geophysical flows (DOI:10.1109/SC41405.2020.00012).
Setting up the problem#
Let’s start by creating a new DeepHyper project workspace. This is a directory where you will create search problem instances that are automatically installed and importable across your Python environment.
deephyper start-project dh_project
A new dh_project directory is created, containing the following files:
dh_project/
dh_project/
__init__.py
setup.py
We can now define our neural architecture search problem inside this directory. Let’s set up a NAS problem called lstm_search as follows:
cd dh_project/dh_project/
deephyper new-problem nas lstm_search
A new NAS problem subdirectory should be in place. This is a Python subpackage containing
sample code in the files __init__.py, load_data.py, search_space.py, and problem.py. Overall, your project directory should look like:
dh_project/
dh_project/
__init__.py
lstm_search/
__init__.py
load_data.py
search_space.py
problem.py
setup.py
Load the data#
Todo
explain how the data were created.
Download the data:
#!/bin/bash
wget "https://github.com/deephyper/tutorials/blob/main/tutorials/12_NAS_LSTM/dh_project/dh_project/lstm_search/True_Train.npy?raw=true" -O True_Train.npy
wget "https://github.com/deephyper/tutorials/blob/main/tutorials/12_NAS_LSTM/dh_project/dh_project/lstm_search/True_Test.npy?raw=true" -O True_Test.npy
Todo
why are the test data used as validation data?
why is the preprocessing fit on both? Should be fit on trained data only?
Transform and preprocess the data:
import os
import numpy as np
from sklearn.preprocessing import MinMaxScaler
# useful to locate data files with respect to this file
HERE = os.path.dirname(os.path.abspath(__file__))
def load_data(verbose=0):
"""
Generate data for linear function -sum(x_i).
Return:
Tuple of Numpy arrays: ``(train_X, train_y), (valid_X, valid_y)``.
"""
rs = np.random.RandomState(2018)
train_data = np.load(os.path.join(HERE, "True_Train.npy"))
valid_data = np.load(os.path.join(HERE, "True_Test.npy"))
features_train = np.transpose(train_data)
features_valid = np.transpose(valid_data)[:700, :]
features = np.concatenate((features_train, features_valid), axis=0)
states = np.copy(features[:, :]) # Rows are time, Columns are state values
scaler = MinMaxScaler()
states = scaler.fit_transform(states)
seq_num = 8
# Need to make batches of 10 input sequences and 1 output
total_size = np.shape(features)[0] - 2 * seq_num
input_seq = np.zeros(shape=(total_size, seq_num, np.shape(states)[1]))
output_seq = np.zeros(shape=(total_size, seq_num, np.shape(states)[1]))
for t in range(total_size):
input_seq[t, :, :] = states[None, t : t + seq_num, :]
output_seq[t, :, :] = states[None, t + seq_num : t + 2 * seq_num, :]
idx = np.arange(total_size)
rs.shuffle(idx)
input_seq = input_seq[idx, :, :]
output_seq = output_seq[idx, :]
# Temporal split
num_samples_train = 900
input_seq_train = input_seq[:num_samples_train, :, :]
output_seq_train = output_seq[:num_samples_train, :, :]
input_seq_valid = input_seq[num_samples_train:, :, :]
output_seq_valid = output_seq[num_samples_train:, :, :]
if verbose:
print("Train Shapes: ", np.shape(input_seq_train), np.shape(output_seq_train))
print("Valid Shapes: ", np.shape(input_seq_valid), np.shape(output_seq_valid))
# Interface to run training data must me respected
return (input_seq_train, output_seq_train), (input_seq_valid, output_seq_valid)
if __name__ == "__main__":
load_data(verbose=1)
Test the function with python load_data.py and get the following output:
Train Shapes: (900, 8, 5) (900, 8, 5)
Valid Shapes: (211, 8, 5) (211, 8, 5)
Performance of a baseline LSTM#
Todo
show the performance of a baseline lstm
Define a neural architecture search space#
import collections
import tensorflow as tf
from deephyper.nas.space import KSearchSpace, SpaceFactory
from deephyper.nas.space.node import ConstantNode, VariableNode
from deephyper.nas.space.op.basic import Zero
from deephyper.nas.space.op.connect import Connect
from deephyper.nas.space.op.merge import AddByProjecting
from deephyper.nas.space.op.op1d import Identity
from deephyper.nas.space.op import operation
# Convert a Keras layer to a DeepHyper operation
Dense = operation(tf.keras.layers.Dense)
LSTM = operation(tf.keras.layers.LSTM)
class StackedLSTMFactory(SpaceFactory):
def build(
self,
input_shape,
output_shape,
num_layers=5,
**kwargs,
):
self.ss = KSearchSpace(input_shape, output_shape)
output_dim = output_shape[1]
source = prev_input = self.ss.input_nodes[0]
# look over skip connections within a range of the 2 previous nodes
anchor_points = collections.deque([source], maxlen=2)
for _ in range(num_layers):
lstm = VariableNode()
self.add_lstm_seq_(lstm)
self.ss.connect(prev_input, lstm)
cmerge = ConstantNode()
cmerge.set_op(AddByProjecting(self.ss, [lstm], activation="relu"))
for anchor in anchor_points:
skipco = VariableNode()
skipco.add_op(Zero())
skipco.add_op(Connect(self.ss, anchor))
self.ss.connect(skipco, cmerge)
# ! for next iter
prev_input = cmerge
anchor_points.append(prev_input)
y = ConstantNode(LSTM(output_dim, return_sequences=True))
self.ss.connect(prev_input, y)
return self.ss
def add_lstm_seq_(self, node):
node.add_op(Identity()) # we do not want to create a layer in this case
for units in range(16, 97, 16):
node.add_op(LSTM(units=units, return_sequences=True))
def create_search_space(
input_shape=(
8,
5,
),
output_shape=(
8,
5,
),
num_layers=10,
**kwargs,
):
return StackedLSTMFactory()(
input_shape, output_shape, num_layers=num_layers, **kwargs
)
if __name__ == "__main__":
shapes = dict(input_shape=(8, 5,), output_shape=(8, 5,))
factory = StackedLSTMFactory()
factory.plot_model(**shapes)
An example of a randomly generated architecture from this search space:
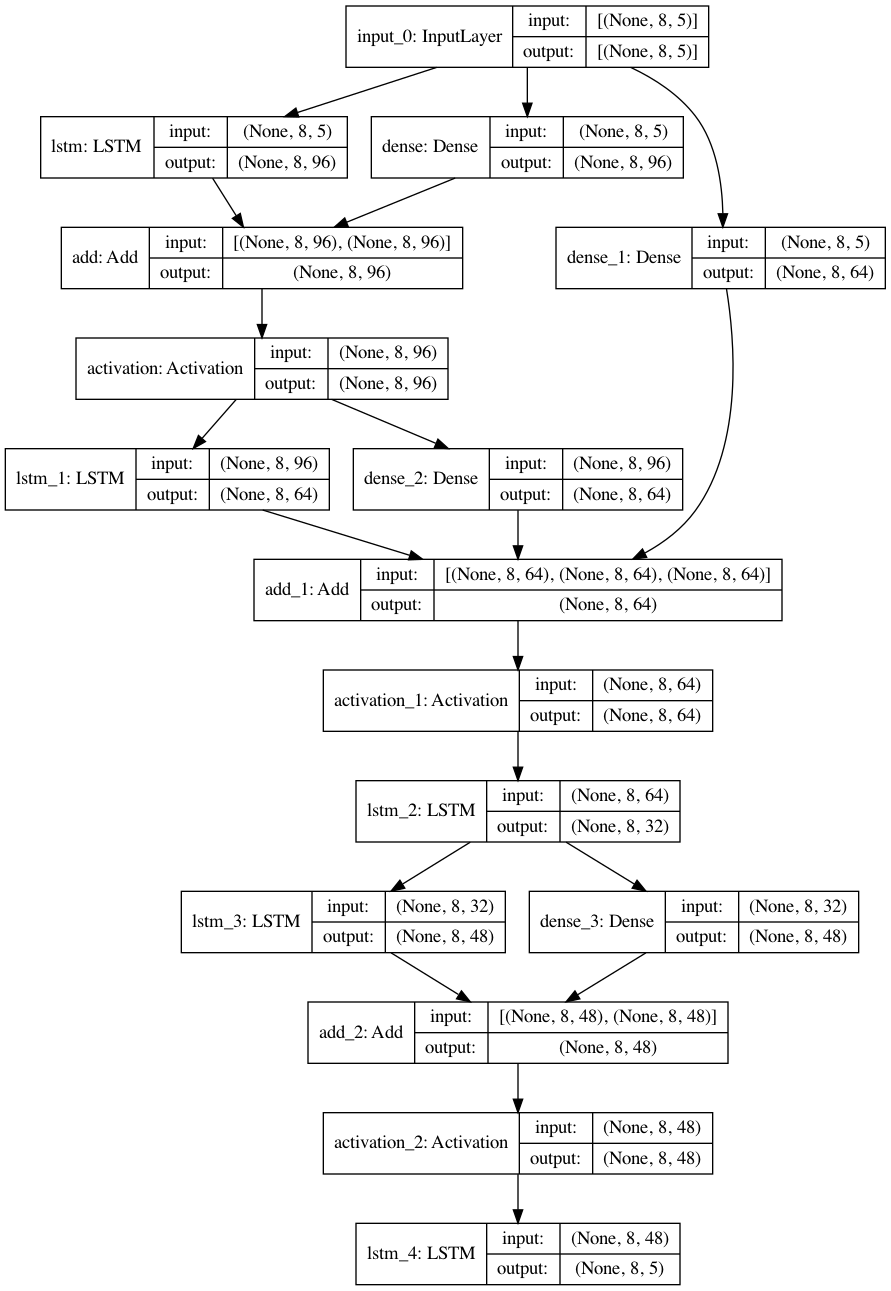
Create a problem instance#
from deephyper.problem import NaProblem
from dh_project.lstm_search.load_data import load_data
from dh_project.lstm_search.search_space import create_search_space
Problem = NaProblem(seed=2019)
Problem.load_data(load_data)
Problem.search_space(create_search_space, num_layers=5)
Problem.hyperparameters(
batch_size=32,
learning_rate=0.001,
optimizer='adam',
num_epochs=100,
callbacks=dict(
EarlyStopping=dict(
monitor='val_r2',
mode='max',
verbose=0,
patience=5
)
)
)
Problem.loss('mse')
Problem.metrics(['r2'])
Problem.objective('val_r2')
# Just to print your problem, to test its definition and imports in the current python environment.
if __name__ == '__main__':
print(Problem)
Execute the search locally#
Everything is ready to run. Let’s remember the structure of our experiment:
lstm_search/
__init__.py
load_data.py
problem.py
search_space.py
Each of these files can also be tested one by one on the local machine (see tutorial-04 for details). Next, we will run a random search (RDM).
deephyper nas random --evaluator ray --problem dh_project.lstm_search.problem.Problem --max-evals 10 --num-workers 2
Note
In order to run DeepHyper locally and on other systems we are using deephyper.evaluator. For local evaluations we can use the deephyper.evaluator.RayEvaluator or the deephyper.evaluator.SubProcessEvaluator.
After the search is over, you will find the following files in your current folder:
deephyper.log
init_infos.json
results.csv
save/
Todo
analyse the resutls of the search (plot + topk)
shows the best model found
deephyper-analytics topk results.csv -k 3 -o topk.json
To visualize or use this best architecture you can recreated the Keras model this way:
import json
import tensorflow as tf
from dh_project.lstm_search.problem import Problem
# Edit the path if necessary
path_to_topk_json = "topk.json"
# Load the json file
with open(path_to_topk_json, "r") as f:
topk = json.load(f)
# Convert the arch_seq (a str now) to a list
arch_seq = json.loads(topk["0"]["arch_seq"])
# Create the Keras model using the problem
model = Problem.get_keras_model(arch_seq)
tf.keras.utils.plot_model(model, "best_model.png")
Then, execute the scrip python best_model.py and visualize the image produced:
