
2. Introduction to Distributed Bayesian Optimization (DBO) with MPI (Communication) and Redis (Storage)#
Author(s): Joceran Gouneau & Romain Egele.
In this tutorial we show how to use the Distributed Bayesian Optimization (DBO) search algorithm with MPI (for the communication) and Redis (for the storage service) to perform hyperparameter optimization on the Ackley function.
2.1. MPI and Redis requirements#
Before starting, make sure you have an installed implementation of MPI (e.g., openmpi) and RedisJson. The following instructions can be followed to install Redis with the RedisJSON plugin:
$ # Activate first you conda environment
$ conda activate dh
$ # Then create a Spack environment to install RedisJson
$ spack env create redisjson
$ spack env activate redisjson
$ spack repo add deephyper-spack-packages
$ spack add redisjson
$ spack install
2.2. Definition of the problem : the Ackley function#
Note
We are using this function to emulate a realistic problem while keeping the definition of the hyperparameter search space and run function as simple as possible ; if you are searching for neural network use cases we redirect you to our others tutorials.
First we have to define the Hyperparameter search space as well as the run function, which, given a certain config of hyperparameters, should return the objective we want to maximize. We are computing the 10-D (\(d = 10\)) Ackley function with \(a = 20\), \(b = 0.2\) and \(c = 2\pi\) and want to find its minimum \(f(x=(0, \dots , 0)) = 0\) on the domain \([-32.768, 32.768]^{10}\).
Thus we define the hyperparameter problem as \(x_i \in [-32.768, 32.768]~ \forall i \in [|0,9|]\) and the objective returned by the run function as \(-f(x)\).
ackley.py#import time
import numpy as np
from deephyper.problem import HpProblem
d = 10
domain = (-32.768, 32.768)
hp_problem = HpProblem()
for i in range(d):
hp_problem.add_hyperparameter(domain, f"x{i}")
def ackley(x, a=20, b=0.2, c=2*np.pi):
d = len(x)
s1 = np.sum(x ** 2)
s2 = np.sum(np.cos(c * x))
term1 = -a * np.exp(-b * np.sqrt(s1 / d))
term2 = -np.exp(s2 / d)
y = term1 + term2 + a + np.exp(1)
return y
def run(config):
time.sleep(1)
x = np.array([config[f"x{i}"] for i in range(d)])
x = np.asarray_chkfinite(x) # ValueError if any NaN or Inf
return -ackley(x)
2.3. Definition of the distributed Bayesian optimization search (DBO)#
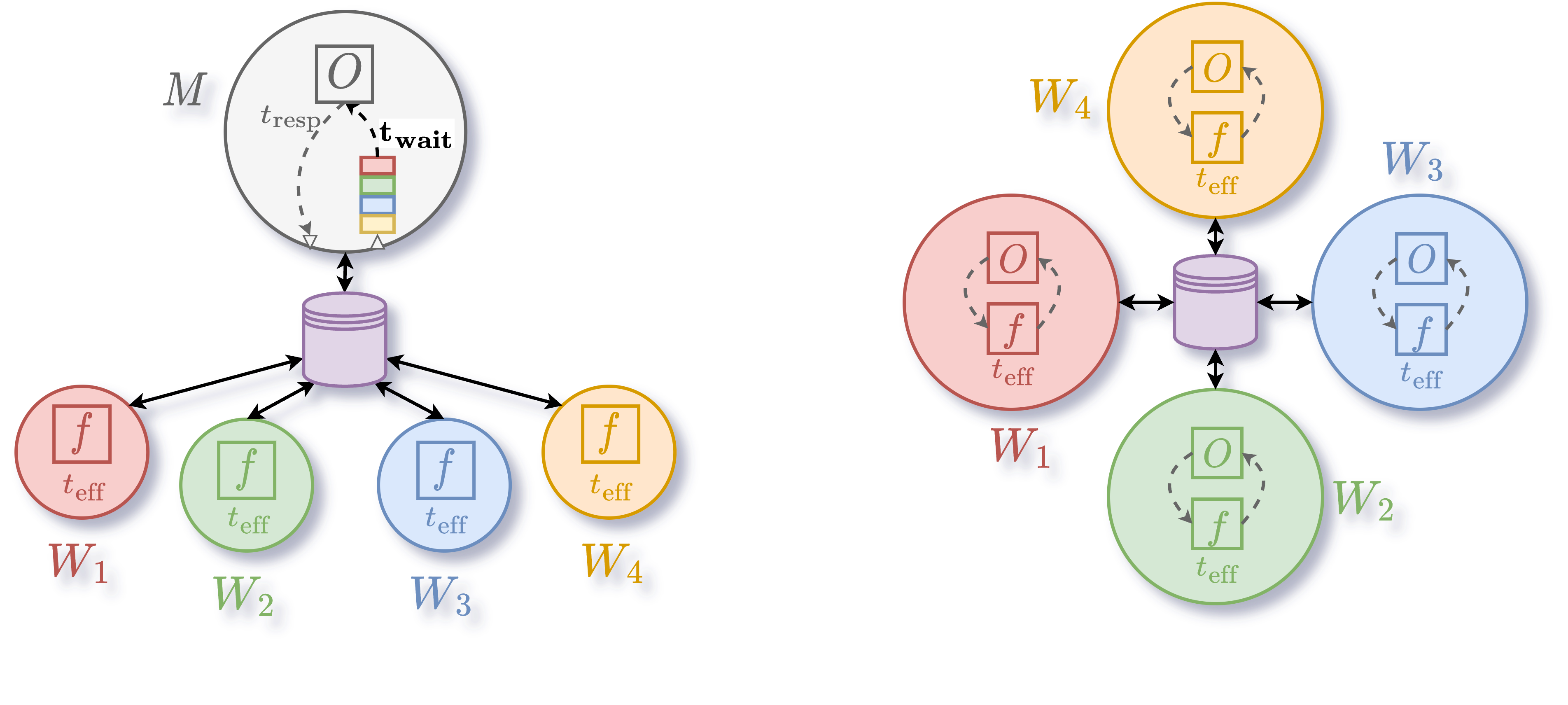
DBO (right) is very similar to Centralized Bayesian Optimization (CBO) (left) in the sense that we iteratively generate new configurations with an optimizer \(O\), evaluate them on Workers \(W\) by calling the black-box function \(f\) which takes \(t_{eff}\) time to be computed, and fit the optimizer on the history of the search (the configuration/objective pairs) to generate better configurations. The only difference is that with CBO the fitting of the optimizer and generation of new configurations is centralized on a Manager \(M\), while with DBO each worker has its own optimizer and these operations are parallelized. This difference makes DBO a preferable choice when the run function is relatively fast and the number of workers increasing; with a large enough number of workers the fit of the optimizer (which has to be performed each time we generate a configuration) starts to take more time than the run function takes to be evaluated : at that point we obtain a congestion on the manager and therefore workers become idle because waiting for a new configuration to be evaluated. DBO avoid this type of congestion issue by attributing one optimizer per worker and performing asynchronous communication between optimizers.
DBO can be formally described in the following algorithm:

2.3.1. Initialize MPI#
First we need to initialize MPI and get the communicator and the rank of the current worker, we can also import all required modules:
mpi_dbo_with_redis.py#from mpi4py import MPI
from deephyper.search.hps import MPIDistributedBO
from ackley import hp_problem, run
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
2.3.2. Create the Evaluator#
In DBO, the independant search instances in different ranks are communicating with each other through a storage. The storage is an instance of the deephyper.evaluator.storage.Storage class and is used to store the search data (e.g., the configuration/objective pairs).
mpi_dbo_with_redis.py## Each rank creates a RedisStorage client and connects to the storage server
# indicated by host:port. Then, the storage is passed to the evaluator.
evaluator = MPIDistributedBO.bootstrap_evaluator(
run,
evaluator_type="serial", # one worker to evaluate the run-function per rank
storage_type="redis",
storage_kwargs={
"host": "localhost",
"port": 6379,
},
comm=comm,
root=0,
)
# A new search was created by the bootstrap_evaluator function.
if rank == 0:
print(f"Search Id: {evaluator._search_id}")
2.3.3. Create and Run the Search#
The search can now be created using the previously created evaluator and the same communicator comm:
mpi_dbo_with_redis.py## Define the Periodic Exponential Decay scheduler to avoid over-exploration
# When increasing the number of parallel workers. This mechanism will enforce
# All agent to periodically converge to the exploitation regime of Bayesian Optimization.
scheduler = {
"type": "periodic-exp-decay",
"periode": 50,
"rate": 0.1,
}
# The Distributed Bayesian Optimization search instance is created
# With the corresponding evaluator and communicator.
search = MPIDistributedBO(
hp_problem, evaluator, log_dir="mpi-distributed-log", comm=comm, scheduler=scheduler
)
# The search is started with a timeout of 10 seconds.
results = search.search(timeout=10)
The search can now be executed. First, start the Redis database server:
$ redis-server $(spack find --path redisjson | grep -o "/.*/redisjson.*")/redis.conf
Once the service is started and runs in the background, you can start the search with the following command:
$ mpirun -np 4 python mpi_dbo_with_redis.py
Now check the mpi-distributed-log/results.csv file and it should contain about 40 (1 seconde per evaluator,
4 search instancidated and 10 secondes in total) configurations and objectives (a bit less given some overheads).