
Note
Click here to download the full example code
Transfer Learning for Hyperparameter Search#
Author(s): Romain Egele.
In this example we present how to apply transfer-learning for hyperparameter search. Let’s assume you have a bunch of similar tasks for example the search of neural networks hyperparameters for different datasets. You can easily imagine that close choices of hyperparameters can perform well these different datasets even if some light additional tuning can help improve the performance. Therefore, you can perform an expensive search once to then reuse the explored set of hyperparameters of thid search and bias the following search with it. Here, we will use a cheap to compute and easy to understand example where we maximise the \(f(x) = -\sum_{i=0}^{n-1}\) function. In this case the size of the problem can be defined by the variable \(n\). We will start by optimizing the small-size problem where \(n=1\), then apply transfer-learning from to optimize the larger-size problem where \(n=2\) and visualize the difference if were not to apply transfer-learning on this larger problem instance.
Let us start by defining the run-functions of the small and large scale problems:
import functools
def run(config: dict, N: int) -> float:
y = -sum([config[f"x{i}"] ** 2 for i in range(N)])
return y
run_small = functools.partial(run, N=1)
run_large = functools.partial(run, N=2)
Then, we can define the hyperparameter problem space based on \(n\)
Out:
Configuration space object:
Hyperparameters:
x0, Type: UniformFloat, Range: [-10.0, 10.0], Default: 0.0
Out:
Configuration space object:
Hyperparameters:
x0, Type: UniformFloat, Range: [-10.0, 10.0], Default: 0.0
x1, Type: UniformFloat, Range: [-10.0, 10.0], Default: 0.0
Then, we define setup the search and execute it:
from deephyper.evaluator import Evaluator
from deephyper.evaluator.callback import TqdmCallback
from deephyper.search.hps import CBO
results = {}
max_evals = 20
evaluator_small = Evaluator.create(
run_small, method="serial", method_kwargs={"callbacks": [TqdmCallback()]}
)
search_small = CBO(problem_small, evaluator_small, random_state=42)
results["Small"] = search_small.search(max_evals)
Out:
0%| | 0/20 [00:00<?, ?it/s]
5%|5 | 1/20 [00:00<00:00, 10894.30it/s, failures=0, objective=-35.2]
10%|# | 2/20 [00:00<00:00, 196.12it/s, failures=0, objective=-23.6]
15%|#5 | 3/20 [00:00<00:00, 171.98it/s, failures=0, objective=-23.6]
20%|## | 4/20 [00:00<00:00, 162.69it/s, failures=0, objective=-23.6]
25%|##5 | 5/20 [00:00<00:00, 158.97it/s, failures=0, objective=-23.6]
30%|### | 6/20 [00:00<00:00, 156.15it/s, failures=0, objective=-.545]
35%|###5 | 7/20 [00:00<00:00, 53.52it/s, failures=0, objective=-.545]
35%|###5 | 7/20 [00:00<00:00, 53.52it/s, failures=0, objective=-.545]
40%|#### | 8/20 [00:00<00:00, 53.52it/s, failures=0, objective=-.545]
45%|####5 | 9/20 [00:00<00:00, 53.52it/s, failures=0, objective=-.545]
50%|##### | 10/20 [00:00<00:00, 53.52it/s, failures=0, objective=-.545]
55%|#####5 | 11/20 [00:00<00:00, 53.52it/s, failures=0, objective=-.469]
60%|###### | 12/20 [00:00<00:00, 53.52it/s, failures=0, objective=-.469]
65%|######5 | 13/20 [00:00<00:00, 13.14it/s, failures=0, objective=-.469]
65%|######5 | 13/20 [00:00<00:00, 13.14it/s, failures=0, objective=-.469]
70%|####### | 14/20 [00:01<00:00, 13.14it/s, failures=0, objective=-.469]
75%|#######5 | 15/20 [00:01<00:00, 13.14it/s, failures=0, objective=-.469]
80%|######## | 16/20 [00:01<00:00, 7.85it/s, failures=0, objective=-.469]
80%|######## | 16/20 [00:01<00:00, 7.85it/s, failures=0, objective=-.469]
85%|########5 | 17/20 [00:01<00:00, 7.85it/s, failures=0, objective=-.469]
90%|######### | 18/20 [00:02<00:00, 6.56it/s, failures=0, objective=-.469]
90%|######### | 18/20 [00:02<00:00, 6.56it/s, failures=0, objective=-.469]
95%|#########5| 19/20 [00:02<00:00, 6.56it/s, failures=0, objective=-.469]
100%|##########| 20/20 [00:02<00:00, 5.42it/s, failures=0, objective=-.469]
100%|##########| 20/20 [00:02<00:00, 5.42it/s, failures=0, objective=-.469]
Out:
0%| | 0/20 [00:00<?, ?it/s]
5%|5 | 1/20 [00:00<00:00, 35848.75it/s, failures=0, objective=-58.7]
10%|# | 2/20 [00:00<00:00, 184.64it/s, failures=0, objective=-58.7]
15%|#5 | 3/20 [00:00<00:00, 140.12it/s, failures=0, objective=-58.7]
20%|## | 4/20 [00:00<00:00, 124.92it/s, failures=0, objective=-30.2]
25%|##5 | 5/20 [00:00<00:00, 116.68it/s, failures=0, objective=-30.2]
30%|### | 6/20 [00:00<00:00, 48.75it/s, failures=0, objective=-30.2]
30%|### | 6/20 [00:00<00:00, 48.75it/s, failures=0, objective=-30.2]
35%|###5 | 7/20 [00:00<00:00, 48.75it/s, failures=0, objective=-30.2]
40%|#### | 8/20 [00:00<00:00, 48.75it/s, failures=0, objective=-30.2]
45%|####5 | 9/20 [00:00<00:00, 48.75it/s, failures=0, objective=-30.2]
50%|##### | 10/20 [00:00<00:00, 48.75it/s, failures=0, objective=-1.84]
55%|#####5 | 11/20 [00:00<00:00, 26.15it/s, failures=0, objective=-1.84]
55%|#####5 | 11/20 [00:00<00:00, 26.15it/s, failures=0, objective=-1.84]
60%|###### | 12/20 [00:00<00:00, 26.15it/s, failures=0, objective=-1.84]
65%|######5 | 13/20 [00:00<00:00, 26.15it/s, failures=0, objective=-1.34]
70%|####### | 14/20 [00:01<00:00, 26.15it/s, failures=0, objective=-1.34]
75%|#######5 | 15/20 [00:01<00:00, 8.32it/s, failures=0, objective=-1.34]
75%|#######5 | 15/20 [00:01<00:00, 8.32it/s, failures=0, objective=-1.34]
80%|######## | 16/20 [00:01<00:00, 8.32it/s, failures=0, objective=-1.34]
85%|########5 | 17/20 [00:01<00:00, 6.45it/s, failures=0, objective=-1.34]
85%|########5 | 17/20 [00:01<00:00, 6.45it/s, failures=0, objective=-1.34]
90%|######### | 18/20 [00:02<00:00, 6.45it/s, failures=0, objective=-1.34]
95%|#########5| 19/20 [00:02<00:00, 5.60it/s, failures=0, objective=-1.34]
95%|#########5| 19/20 [00:02<00:00, 5.60it/s, failures=0, objective=-1.34]
100%|##########| 20/20 [00:02<00:00, 5.00it/s, failures=0, objective=-1.34]
100%|##########| 20/20 [00:02<00:00, 5.00it/s, failures=0, objective=-1.34]
Out:
/Users/romainegele/Documents/Argonne/deephyper/deephyper/search/hps/_cbo.py:552: UserWarning: The value of q=0.9 is replaced by q_max=0.5 because a minimum of 10 results are required to perform transfer-learning!
warnings.warn(
[<sdv.constraints.tabular.ScalarRange object at 0x2a7452130>]
0%| | 0/100 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/100 [00:00<?, ?it/s]
Sampling rows: 100%|##########| 100/100 [00:00<00:00, 14671.04it/s]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 208719.61it/s]
0%| | 0/20 [00:00<?, ?it/s]
5%|5 | 1/20 [00:00<00:00, 26214.40it/s, failures=0, objective=-35.2]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 206620.03it/s]
10%|# | 2/20 [00:00<00:00, 31.59it/s, failures=0, objective=-25.8]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 207891.99it/s]
15%|#5 | 3/20 [00:00<00:00, 23.81it/s, failures=0, objective=-25.8]
15%|#5 | 3/20 [00:00<00:00, 23.81it/s, failures=0, objective=-24.9]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 204780.00it/s]
20%|## | 4/20 [00:00<00:00, 23.81it/s, failures=0, objective=-24.9]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 212486.02it/s]
25%|##5 | 5/20 [00:00<00:00, 23.81it/s, failures=0, objective=-24.9]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 208004.36it/s]
30%|### | 6/20 [00:00<00:00, 18.73it/s, failures=0, objective=-24.9]
30%|### | 6/20 [00:00<00:00, 18.73it/s, failures=0, objective=-1.18]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 207496.03it/s]
35%|###5 | 7/20 [00:00<00:00, 18.73it/s, failures=0, objective=-1.18]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 216745.33it/s]
40%|#### | 8/20 [00:00<00:00, 17.93it/s, failures=0, objective=-1.18]
40%|#### | 8/20 [00:00<00:00, 17.93it/s, failures=0, objective=-1.18]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 214519.36it/s]
45%|####5 | 9/20 [00:00<00:00, 17.93it/s, failures=0, objective=-1.18]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 216229.10it/s]
50%|##### | 10/20 [00:00<00:00, 14.09it/s, failures=0, objective=-1.18]
50%|##### | 10/20 [00:00<00:00, 14.09it/s, failures=0, objective=-1.18]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 216376.35it/s]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 214873.23it/s]
55%|#####5 | 11/20 [00:00<00:00, 14.09it/s, failures=0, objective=-1.18]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 215082.59it/s]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 215307.82it/s]
60%|###### | 12/20 [00:01<00:01, 6.45it/s, failures=0, objective=-1.18]
60%|###### | 12/20 [00:01<00:01, 6.45it/s, failures=0, objective=-1.18]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 215592.24it/s]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 215516.92it/s]
65%|######5 | 13/20 [00:01<00:01, 6.45it/s, failures=0, objective=-1.18]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 214209.31it/s]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 215253.68it/s]
70%|####### | 14/20 [00:02<00:01, 4.50it/s, failures=0, objective=-1.18]
70%|####### | 14/20 [00:02<00:01, 4.50it/s, failures=0, objective=-1.18]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 213215.13it/s]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 214980.06it/s]
75%|#######5 | 15/20 [00:02<00:01, 4.13it/s, failures=0, objective=-1.18]
75%|#######5 | 15/20 [00:02<00:01, 4.13it/s, failures=0, objective=-1.18]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 215077.07it/s]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 214597.29it/s]
80%|######## | 16/20 [00:02<00:01, 3.82it/s, failures=0, objective=-1.18]
80%|######## | 16/20 [00:02<00:01, 3.82it/s, failures=0, objective=-1.18]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 214800.60it/s]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 215145.47it/s]
85%|########5 | 17/20 [00:03<00:00, 3.56it/s, failures=0, objective=-1.18]
85%|########5 | 17/20 [00:03<00:00, 3.56it/s, failures=0, objective=-1.18]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 214786.30it/s]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 215646.56it/s]
90%|######### | 18/20 [00:03<00:00, 3.31it/s, failures=0, objective=-1.18]
90%|######### | 18/20 [00:03<00:00, 3.31it/s, failures=0, objective=-1.18]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 216154.44it/s]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 213770.42it/s]
95%|#########5| 19/20 [00:03<00:00, 3.00it/s, failures=0, objective=-1.18]
95%|#########5| 19/20 [00:03<00:00, 3.00it/s, failures=0, objective=-1.18]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 214832.51it/s]
0%| | 0/10000 [00:00<?, ?it/s]
Sampling rows: 0%| | 0/10000 [00:00<?, ?it/s]/Users/romainegele/miniforge3/envs/dh-arm/lib/python3.9/site-packages/ctgan/data_transformer.py:188: FutureWarning: In a future version, `df.iloc[:, i] = newvals` will attempt to set the values inplace instead of always setting a new array. To retain the old behavior, use either `df[df.columns[i]] = newvals` or, if columns are non-unique, `df.isetitem(i, newvals)`
data.iloc[:, 1] = np.argmax(column_data[:, 1:], axis=1)
Sampling rows: 100%|##########| 10000/10000 [00:00<00:00, 214860.02it/s]
100%|##########| 20/20 [00:04<00:00, 2.97it/s, failures=0, objective=-1.18]
100%|##########| 20/20 [00:04<00:00, 2.97it/s, failures=0, objective=-1.18]
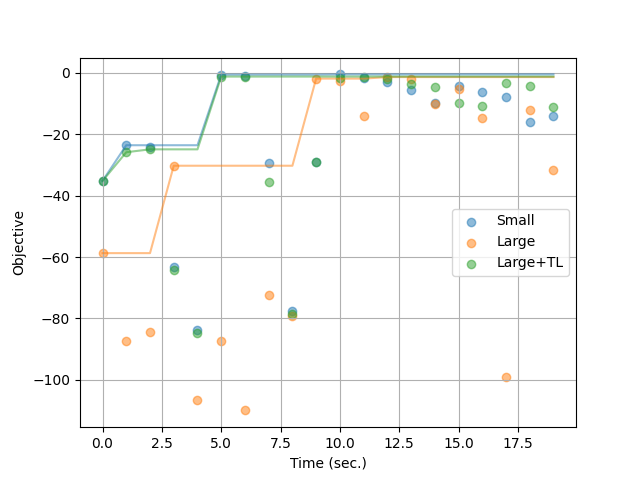
Finally, we compare the results and quickly see that transfer-learning provided a consequant speed-up for the search:
import matplotlib.pyplot as plt
plt.figure()
for strategy, df in results.items():
x = [i for i in range(len(df))]
plt.scatter(x, df.objective, label=strategy, alpha=0.5)
plt.plot(x, df.objective.cummax(), alpha=0.5)
plt.xlabel("Time (sec.)")
plt.ylabel("Objective")
plt.grid()
plt.legend()
plt.show()
Total running time of the script: ( 0 minutes 12.852 seconds)