
2. Hyperparameter search for classification with Tabular data (Keras)#
![]()
In this tutorial we present how to use hyperparameter optimization on a basic example from the Keras documentation.
Reference: This tutorial is based on materials from the Keras Documentation: Structured data classification from scratch
Let us start with installing DeepHyper!
Warning
This tutorial should be run with tensorflow>=2.6.
[1]:
try:
import deephyper
print(deephyper.__version__)
except (ImportError, ModuleNotFoundError):
!pip install deephyper
try:
import ray
except (ImportError, ModuleNotFoundError):
!pip install ray
0.6.0
Note
The following environment variables can be used to avoid the logging of some Tensorflow DEBUG, INFO and WARNING statements.
[2]:
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = str(3)
os.environ["AUTOGRAPH_VERBOSITY"] = str(0)
2.1. Imports#
Warning
It is important to follow the import strategy import tensorflow as tf to prevent serialization errors that will crash the search.
The import strategy from the original Keras tutorial (shown below):
from tensorflow import keras
from tensorflow.keras import layers
...
from tensorflow.keras.layers import IntegerLookup
from tensorflow.keras.layers import Normalization
from tensorflow.keras.layers import StringLookup
resulted in non-serializable data, preventing the search from executing in parallel.
[3]:
import json
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow.keras.backend as K
Note
The following can be used to detect if GPU devices are available on the current host. Therefore, this notebook will automatically adapt the parallel execution based on the resources available locally. However, this simple code will not detect the ressources from multiple nodes.
[4]:
from tensorflow.python.client import device_lib
def get_available_gpus():
local_device_protos = device_lib.list_local_devices()
return [x.name for x in local_device_protos if x.device_type == "GPU"]
n_gpus = len(get_available_gpus())
if n_gpus > 1:
n_gpus -= 1
is_gpu_available = n_gpus > 0
if is_gpu_available:
print(f"{n_gpus} GPU{'s are' if n_gpus > 1 else ' is'} available.")
else:
print("No GPU available")
No GPU available
2.2. The dataset (from Keras.io)#
The dataset is provided by the Cleveland Clinic Foundation for Heart Disease. It’s a CSV file with 303 rows. Each row contains information about a patient (a sample), and each column describes an attribute of the patient (a feature). We use the features to predict whether a patient has a heart disease (binary classification).
Here’s the description of each feature:
Column |
Description |
Feature Type |
|---|---|---|
Age |
Age in years |
Numerical |
Sex |
(1 = male; 0 = female) |
Categorical |
CP |
Chest pain type (0, 1, 2, 3, 4) |
Categorical |
Trestbpd |
Resting blood pressure (in mm Hg on admission) |
Numerical |
Chol |
Serum cholesterol in mg/dl |
Numerical |
FBS |
fasting blood sugar in 120 mg/dl (1 = true; 0 = false) |
Categorical |
RestECG |
Resting electrocardiogram results (0, 1, 2) |
Categorical |
Thalach |
Maximum heart rate achieved |
Numerical |
Exang |
Exercise induced angina (1 = yes; 0 = no) |
Categorical |
Oldpeak |
ST depression induced by exercise relative to rest |
Numerical |
Slope |
Slope of the peak exercise ST segment |
Numerical |
CA |
Number of major vessels (0-3) colored by fluoroscopy |
Both numerical & categorical |
Thal |
3 = normal; 6 = fixed defect; 7 = reversible defect |
Categorical |
Target |
Diagnosis of heart disease (1 = true; 0 = false) |
Target |
[5]:
def load_data():
file_url = "http://storage.googleapis.com/download.tensorflow.org/data/heart.csv"
dataframe = pd.read_csv(file_url)
val_dataframe = dataframe.sample(frac=0.2, random_state=1337)
train_dataframe = dataframe.drop(val_dataframe.index)
return train_dataframe, val_dataframe
def dataframe_to_dataset(dataframe):
dataframe = dataframe.copy()
labels = dataframe.pop("target")
ds = tf.data.Dataset.from_tensor_slices((dict(dataframe), labels))
ds = ds.shuffle(buffer_size=len(dataframe))
return ds
2.3. Preprocessing & encoding of features#
The next cells use tf.keras.layers.Normalization() to apply standard scaling on the features.
Then, the tf.keras.layers.StringLookup and tf.keras.layers.IntegerLookup are used to encode categorical variables.
[6]:
def encode_numerical_feature(feature, name, dataset):
# Create a Normalization layer for our feature
normalizer = tf.keras.layers.Normalization()
# Prepare a Dataset that only yields our feature
feature_ds = dataset.map(lambda x, y: x[name])
feature_ds = feature_ds.map(lambda x: tf.expand_dims(x, -1))
# Learn the statistics of the data
normalizer.adapt(feature_ds)
# Normalize the input feature
encoded_feature = normalizer(feature)
return encoded_feature
def encode_categorical_feature(feature, name, dataset, is_string):
lookup_class = (
tf.keras.layers.StringLookup if is_string else tf.keras.layers.IntegerLookup
)
# Create a lookup layer which will turn strings into integer indices
lookup = lookup_class(output_mode="binary")
# Prepare a Dataset that only yields our feature
feature_ds = dataset.map(lambda x, y: x[name])
feature_ds = feature_ds.map(lambda x: tf.expand_dims(x, -1))
# Learn the set of possible string values and assign them a fixed integer index
lookup.adapt(feature_ds)
# Turn the string input into integer indices
encoded_feature = lookup(feature)
return encoded_feature
2.4. Define the run-function#
The run-function defines how the objective that we want to maximize is computed. It takes a config dictionary as input and often returns a scalar value that we want to maximize. The config contains a sample value of hyperparameters that we want to tune. In this example we will search for:
units(default value:32)activation(default value:"relu")dropout_rate(default value:0.5)num_epochs(default value:50)batch_size(default value:32)learning_rate(default value:1e-3)
A hyperparameter value can be acessed easily in the dictionary through the corresponding key, for example config["units"].
[7]:
def count_params(model: tf.keras.Model) -> dict:
"""Evaluate the number of parameters of a Keras model.
Args:
model (tf.keras.Model): a Keras model.
Returns:
dict: a dictionary with the number of trainable ``"num_parameters_train"`` and
non-trainable parameters ``"num_parameters"``.
"""
def count_or_null(p):
try:
return K.count_params(p)
except:
return 0
num_parameters_train = int(
np.sum([count_or_null(p) for p in model.trainable_weights])
)
num_parameters = int(
np.sum([count_or_null(p) for p in model.non_trainable_weights])
)
return {
"num_parameters": num_parameters,
"num_parameters_train": num_parameters_train,
}
[8]:
def run(config: dict):
tf.autograph.set_verbosity(0)
# Load data and split into validation set
train_dataframe, val_dataframe = load_data()
train_ds = dataframe_to_dataset(train_dataframe)
val_ds = dataframe_to_dataset(val_dataframe)
train_ds = train_ds.batch(config["batch_size"])
val_ds = val_ds.batch(config["batch_size"])
# Categorical features encoded as integers
sex = tf.keras.Input(shape=(1,), name="sex", dtype="int64")
cp = tf.keras.Input(shape=(1,), name="cp", dtype="int64")
fbs = tf.keras.Input(shape=(1,), name="fbs", dtype="int64")
restecg = tf.keras.Input(shape=(1,), name="restecg", dtype="int64")
exang = tf.keras.Input(shape=(1,), name="exang", dtype="int64")
ca = tf.keras.Input(shape=(1,), name="ca", dtype="int64")
# Categorical feature encoded as string
thal = tf.keras.Input(shape=(1,), name="thal", dtype="string")
# Numerical features
age = tf.keras.Input(shape=(1,), name="age")
trestbps = tf.keras.Input(shape=(1,), name="trestbps")
chol = tf.keras.Input(shape=(1,), name="chol")
thalach = tf.keras.Input(shape=(1,), name="thalach")
oldpeak = tf.keras.Input(shape=(1,), name="oldpeak")
slope = tf.keras.Input(shape=(1,), name="slope")
all_inputs = [
sex,
cp,
fbs,
restecg,
exang,
ca,
thal,
age,
trestbps,
chol,
thalach,
oldpeak,
slope,
]
# Integer categorical features
sex_encoded = encode_categorical_feature(sex, "sex", train_ds, False)
cp_encoded = encode_categorical_feature(cp, "cp", train_ds, False)
fbs_encoded = encode_categorical_feature(fbs, "fbs", train_ds, False)
restecg_encoded = encode_categorical_feature(restecg, "restecg", train_ds, False)
exang_encoded = encode_categorical_feature(exang, "exang", train_ds, False)
ca_encoded = encode_categorical_feature(ca, "ca", train_ds, False)
# String categorical features
thal_encoded = encode_categorical_feature(thal, "thal", train_ds, True)
# Numerical features
age_encoded = encode_numerical_feature(age, "age", train_ds)
trestbps_encoded = encode_numerical_feature(trestbps, "trestbps", train_ds)
chol_encoded = encode_numerical_feature(chol, "chol", train_ds)
thalach_encoded = encode_numerical_feature(thalach, "thalach", train_ds)
oldpeak_encoded = encode_numerical_feature(oldpeak, "oldpeak", train_ds)
slope_encoded = encode_numerical_feature(slope, "slope", train_ds)
all_features = tf.keras.layers.concatenate(
[
sex_encoded,
cp_encoded,
fbs_encoded,
restecg_encoded,
exang_encoded,
slope_encoded,
ca_encoded,
thal_encoded,
age_encoded,
trestbps_encoded,
chol_encoded,
thalach_encoded,
oldpeak_encoded,
]
)
x = tf.keras.layers.Dense(config["units"], activation=config["activation"])(
all_features
)
x = tf.keras.layers.Dropout(config["dropout_rate"])(x)
output = tf.keras.layers.Dense(1, activation="sigmoid")(x)
model = tf.keras.Model(all_inputs, output)
optimizer = tf.keras.optimizers.Adam(learning_rate=config["learning_rate"])
model.compile(optimizer, "binary_crossentropy", metrics=["accuracy"])
history = model.fit(
train_ds, epochs=config["num_epochs"], validation_data=val_ds, verbose=0
)
objective = history.history["val_accuracy"][-1]
metadata = {
"loss": history.history["loss"],
"val_loss": history.history["val_loss"],
"accuracy": history.history["accuracy"],
"val_accuracy": history.history["val_accuracy"],
}
metadata = {k:json.dumps(v) for k,v in metadata.items()}
metadata.update(count_params(model))
return {"objective": objective, "metadata": metadata}
The objective maximised by DeepHyper is the scalar value returned by the run-function.
In this tutorial it corresponds to the validation accuracy of the last epoch of training which we retrieve in the History object returned by the model.fit(...) call.
...
history = model.fit(
train_ds, epochs=config["num_epochs"], validation_data=val_ds, verbose=0
)
return history.history["val_accuracy"][-1]
...
Using an objective like max(history.history['val_accuracy']) can have undesired side effects.
For example, it is possible that the training curves will overshoot a local maximum, resulting in a model without the capacity to flexibly adapt to new data in the future.
2.5. Define the Hyperparameter optimization problem#
Hyperparameter ranges are defined using the following syntax:
Discrete integer ranges are generated from a tuple
(lower: int, upper: int)Continuous prarameters are generated from a tuple
(lower: float, upper: float)Categorical or nonordinal hyperparameter ranges can be given as a list of possible values
[val1, val2, ...]
[9]:
from deephyper.problem import HpProblem
# Creation of an hyperparameter problem
problem = HpProblem()
# Discrete hyperparameter (sampled with uniform prior)
problem.add_hyperparameter((8, 128), "units", default_value=32)
problem.add_hyperparameter((10, 100), "num_epochs", default_value=50)
# Categorical hyperparameter (sampled with uniform prior)
ACTIVATIONS = [
"elu", "gelu", "hard_sigmoid", "linear", "relu", "selu",
"sigmoid", "softplus", "softsign", "swish", "tanh",
]
problem.add_hyperparameter(ACTIVATIONS, "activation", default_value="relu")
# Real hyperparameter (sampled with uniform prior)
problem.add_hyperparameter((0.0, 0.6), "dropout_rate", default_value=0.5)
# Discrete and Real hyperparameters (sampled with log-uniform)
problem.add_hyperparameter((8, 256, "log-uniform"), "batch_size", default_value=32)
problem.add_hyperparameter((1e-5, 1e-2, "log-uniform"), "learning_rate", default_value=1e-3)
problem
[9]:
Configuration space object:
Hyperparameters:
activation, Type: Categorical, Choices: {elu, gelu, hard_sigmoid, linear, relu, selu, sigmoid, softplus, softsign, swish, tanh}, Default: relu
batch_size, Type: UniformInteger, Range: [8, 256], Default: 32, on log-scale
dropout_rate, Type: UniformFloat, Range: [0.0, 0.6], Default: 0.5
learning_rate, Type: UniformFloat, Range: [1e-05, 0.01], Default: 0.001, on log-scale
num_epochs, Type: UniformInteger, Range: [10, 100], Default: 50
units, Type: UniformInteger, Range: [8, 128], Default: 32
2.6. Evaluate a default configuration#
We evaluate the performance of the default set of hyperparameters provided in the Keras tutorial.
[10]:
import ray
# We launch the Ray run-time depending of the detected local ressources
# and execute the `run` function with the default configuration
# WARNING: in the case of GPUs it is important to follow this scheme
# to avoid multiple processes (Ray workers vs current process) to lock
# the same GPU.
if is_gpu_available:
if not(ray.is_initialized()):
ray.init(num_cpus=n_gpus, num_gpus=n_gpus, log_to_driver=False)
run_default = ray.remote(num_cpus=1, num_gpus=1)(run)
out = ray.get(run_default.remote(problem.default_configuration))
else:
if not(ray.is_initialized()):
ray.init(num_cpus=1, log_to_driver=False)
run_default = run
out = run_default(problem.default_configuration)
objective_default = out["objective"]
metadata_default = out["metadata"]
print(f"Accuracy Default Configuration: {objective_default:.3f}")
print("Metadata Default Configuration")
for k,v in out["metadata"].items():
print(f"\t- {k}: {v}")
2023-08-21 15:42:47,612 INFO worker.py:1612 -- Started a local Ray instance. View the dashboard at http://127.0.0.1:8265
WARNING:absl:At this time, the v2.11+ optimizer `tf.keras.optimizers.Adam` runs slowly on M1/M2 Macs, please use the legacy Keras optimizer instead, located at `tf.keras.optimizers.legacy.Adam`.
WARNING:absl:There is a known slowdown when using v2.11+ Keras optimizers on M1/M2 Macs. Falling back to the legacy Keras optimizer, i.e., `tf.keras.optimizers.legacy.Adam`.
Accuracy Default Configuration: 0.820
Metadata Default Configuration
- loss: [0.7349893450737, 0.7119344472885132, 0.6686969995498657, 0.5915975570678711, 0.5431504845619202, 0.5246548056602478, 0.5342034697532654, 0.4842718839645386, 0.4590907692909241, 0.4603484272956848, 0.4597550332546234, 0.44408705830574036, 0.42013710737228394, 0.42205527424812317, 0.4288969337940216, 0.39178749918937683, 0.4030506908893585, 0.3936038613319397, 0.35945186018943787, 0.37975654006004333, 0.3720925748348236, 0.3669050633907318, 0.38736027479171753, 0.374258428812027, 0.3758077025413513, 0.3406431972980499, 0.3294287323951721, 0.33325862884521484, 0.31861767172813416, 0.35496509075164795, 0.3087666630744934, 0.312923789024353, 0.30307966470718384, 0.32532209157943726, 0.3240409791469574, 0.3106668293476105, 0.31075918674468994, 0.31123799085617065, 0.31748679280281067, 0.3370455205440521, 0.30306127667427063, 0.30984699726104736, 0.2797146141529083, 0.29132482409477234, 0.3014650344848633, 0.32005640864372253, 0.2903410494327545, 0.28734707832336426, 0.28279826045036316, 0.2570137679576874]
- val_loss: [0.7456178665161133, 0.6780385375022888, 0.625544548034668, 0.5850293636322021, 0.5513894557952881, 0.5260460376739502, 0.5064079165458679, 0.4892745316028595, 0.4756909906864166, 0.4652484059333801, 0.4565599262714386, 0.44933125376701355, 0.44344136118888855, 0.4388517737388611, 0.4375801086425781, 0.4364493191242218, 0.432796835899353, 0.43143969774246216, 0.42970556020736694, 0.4274940490722656, 0.42608213424682617, 0.42625632882118225, 0.42683979868888855, 0.42844000458717346, 0.42911961674690247, 0.4305785000324249, 0.43083715438842773, 0.43108829855918884, 0.4328072667121887, 0.4343793988227844, 0.4345102906227112, 0.43473729491233826, 0.4349192678928375, 0.4341476559638977, 0.43471893668174744, 0.4353316128253937, 0.4341714680194855, 0.4331118166446686, 0.4324823021888733, 0.4330752193927765, 0.432032972574234, 0.4320930242538452, 0.433055579662323, 0.43358126282691956, 0.4329754710197449, 0.4332190752029419, 0.4322751760482788, 0.43252894282341003, 0.43424201011657715, 0.4347805976867676]
- accuracy: [0.4917355477809906, 0.5991735458374023, 0.6280992031097412, 0.7066115736961365, 0.7851239442825317, 0.7190082669258118, 0.7520661354064941, 0.7727272510528564, 0.8099173307418823, 0.8099173307418823, 0.8140496015548706, 0.8264462947845459, 0.78925621509552, 0.8057851195335388, 0.8140496015548706, 0.85537189245224, 0.85537189245224, 0.8264462947845459, 0.8347107172012329, 0.8429751992225647, 0.8388429880142212, 0.85537189245224, 0.8264462947845459, 0.8388429880142212, 0.8099173307418823, 0.85537189245224, 0.85537189245224, 0.8719007968902588, 0.8760330677032471, 0.8471074104309082, 0.8842975497245789, 0.8636363744735718, 0.8677685856819153, 0.8801652789115906, 0.8719007968902588, 0.8677685856819153, 0.8801652789115906, 0.8719007968902588, 0.8636363744735718, 0.8636363744735718, 0.8801652789115906, 0.8677685856819153, 0.8925619721412659, 0.8801652789115906, 0.8801652789115906, 0.8760330677032471, 0.8842975497245789, 0.8636363744735718, 0.8966942429542542, 0.9008264541625977]
- val_accuracy: [0.49180328845977783, 0.6557376980781555, 0.7377049326896667, 0.7868852615356445, 0.7868852615356445, 0.8032786846160889, 0.8032786846160889, 0.7868852615356445, 0.7868852615356445, 0.7868852615356445, 0.7868852615356445, 0.7868852615356445, 0.8032786846160889, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8032786846160889, 0.8032786846160889, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8032786846160889, 0.8032786846160889, 0.8196721076965332, 0.8196721076965332, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8196721076965332, 0.8196721076965332]
- num_parameters: 18
- num_parameters_train: 1217
2.7. Define the evaluator object#
Evaluator object allows to change the parallelization backend used by DeepHyper.run_function to be instantiated.method defines the backend (e.g., "ray") and the method_kwargs corresponds to keyword arguments of this chosen method.evaluator = Evaluator.create(run_function, method, method_kwargs)
Once created the evaluator.num_workers gives access to the number of available parallel workers.
Finally, to submit and collect tasks to the evaluator one just needs to use the following interface:
configs = [{"units": 8, ...}, ...]
evaluator.submit(configs)
...
# To collect the first finished task (asynchronous)
tasks_done = evaluator.get("BATCH", size=1)
# To collect all of the pending tasks (synchronous)
tasks_done = evaluator.get("ALL")
Warning
Each Evaluator saves its own state, therefore it is crucial to create a new evaluator when launching a fresh search.
[11]:
from deephyper.evaluator import Evaluator
from deephyper.evaluator.callback import TqdmCallback
def get_evaluator(run_function):
# Default arguments for Ray: 1 worker and 1 worker per evaluation
method_kwargs = {
"num_cpus": 1,
"num_cpus_per_task": 1,
"callbacks": [TqdmCallback()]
}
# If GPU devices are detected then it will create 'n_gpus' workers
# and use 1 worker for each evaluation
if is_gpu_available:
method_kwargs["num_cpus"] = n_gpus
method_kwargs["num_gpus"] = n_gpus
method_kwargs["num_cpus_per_task"] = 1
method_kwargs["num_gpus_per_task"] = 1
evaluator = Evaluator.create(
run_function,
method="ray",
method_kwargs=method_kwargs
)
print(f"Created new evaluator with {evaluator.num_workers} worker{'s' if evaluator.num_workers > 1 else ''} and config: {method_kwargs}", )
return evaluator
evaluator_1 = get_evaluator(run)
Created new evaluator with 1 worker and config: {'num_cpus': 1, 'num_cpus_per_task': 1, 'callbacks': [<deephyper.evaluator.callback.TqdmCallback object at 0x36baafb10>]}
/Users/romainegele/Documents/Argonne/deephyper/deephyper/evaluator/_evaluator.py:127: UserWarning: Applying nest-asyncio patch for IPython Shell!
warnings.warn(
2.8. Define and run the centralized Bayesian optimization search (CBO)#
A primary pillar of hyperparameter search in DeepHyper is given by a centralized Bayesian optimization search (henceforth CBO). CBO may be described in the following algorithm:

Following the parallelized evaluation of these configurations, a low-fidelity and high efficiency model (henceforth “the surrogate”) is devised to reproduce the relationship between the input variables involved in the model (i.e., the choice of hyperparameters) and the outputs (which are generally a measure of validation data accuracy).
After obtaining this surrogate of the validation accuracy, we may utilize ideas from classical methods in Bayesian optimization literature for adaptively sample the search space of hyperparameters.
First, the surrogate is used to obtain an estimate for the mean value of the validation accuracy at a certain sampling location \(x\) in addition to an estimated variance. The latter requirement restricts us to the use of high efficiency data-driven modeling strategies that have inbuilt variance estimates (such as a Gaussian process or Random Forest regressor).
Regions where the mean is high represent opportunities for exploitation and regions where the variance is high represent opportunities for exploration. An optimistic acquisition function called UCB can be constructed using these two quantities:
The unevaluated hyperparameter configurations that maximize the acquisition function are chosen for the next batch of evaluations.
Note that the choice of the variance weighting parameter \(\kappa\) controls the degree of exploration in the hyperparameter search with zero indicating purely exploitation (unseen configurations where the predicted accuracy is highest will be sampled).
The top s configurations are selected for the new batch. The following schematic demonstrates this process:
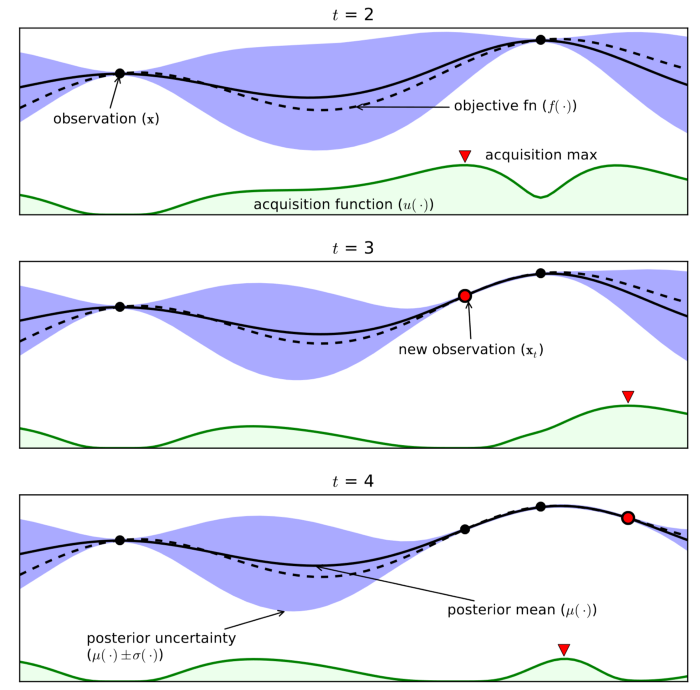
The process of obtaining s configurations relies on the “constant-liar” strategy where a sampled configuration is mapped to a dummy output given by a bulk metric of all the evaluated configurations thus far (such as the maximum, mean or median validation accuracy).
Prior to sampling the next configuration by acquisition function maximization, the surrogate is retrained with the dummy output as a data point. As the true validation accuracy becomes available for one of the sampled configurations, the dummy output is replaced and the surrogate is updated.
This allows for scalable asynchronous (or batch synchronous) sampling of new hyperparameter configurations.
2.8.1. Choice of surrogate model#
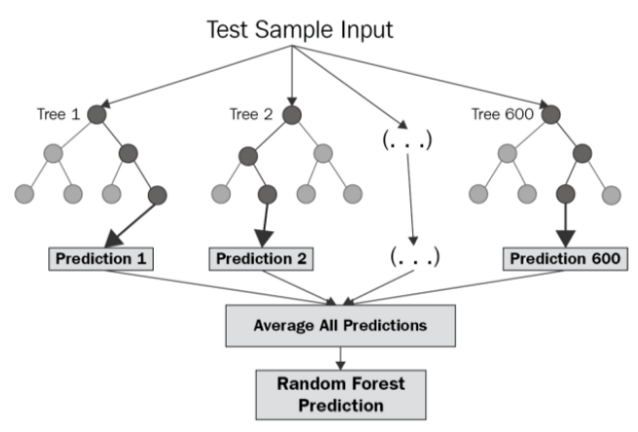
Users should note that our choice of the surrogate is given by the Random Forest regressor due to its ability to handle non-ordinal data (hyperparameter configurations may not be purely continuous or even numerical). Evidence for how they outperform other methods (such as Gaussian processes) is also available in [1]
2.8.1.1. Setup CBO#
We create the CBO using the problem and evaluator defined above.
[12]:
from deephyper.search.hps import CBO
# Uncomment the following line to show the arguments of CBO.
# help(CBO)
[13]:
# Instanciate the search with the problem and the evaluator that we created before
search = CBO(problem, evaluator_1, initial_points=[problem.default_configuration])
Note
All DeepHyper’s search algorithm have two stopping criteria:
max_evals (int): Defines the maximum number of evaluations that we want to perform. Default to -1 for an infinite number.timeout (int): Defines a time budget (in seconds) before stopping the search. Default to None for an infinite time budget.
[14]:
results = search.search(max_evals=25)
Warning
The search call does not output any information about the current status of the search. However, a results.csv file is created in the local directly and can be visualized to see finished tasks.
The returned results is a Pandas Dataframe where columns starting by "p:" are hyperparameters, columns starting by "m:" are additional metadata (from the user or from the Evaluator) as well as the objective value and the job_id:
job_idis a unique identifier corresponding to the order of creation of tasks.objectiveis the value returned by the run-function.m:timestamp_submitis the time (in seconds) when the task was created by the evaluator since the creation of the evaluator.m:timestamp_gatheris the time (in seconds) when the task was received after finishing by the evaluator since the creation of the evaluator.
[15]:
results
[15]:
| p:activation | p:batch_size | p:dropout_rate | p:learning_rate | p:num_epochs | p:units | objective | job_id | m:timestamp_submit | m:timestamp_gather | m:loss | m:val_loss | m:accuracy | m:val_accuracy | m:num_parameters | m:num_parameters_train | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | relu | 32 | 0.500000 | 0.001000 | 50 | 32 | 0.819672 | 0 | 14.062015 | 18.644915 | [0.932179868221283, 0.8672291040420532, 0.7659... | [0.8616852760314941, 0.7722538113594055, 0.698... | [0.3099173605442047, 0.35537189245224, 0.45041... | [0.32786884903907776, 0.39344263076782227, 0.5... | 18 | 1217 |
| 1 | tanh | 34 | 0.416012 | 0.000123 | 32 | 30 | 0.770492 | 1 | 18.689840 | 20.543970 | [0.7169904708862305, 0.7176796197891235, 0.672... | [0.6555299758911133, 0.6463007926940918, 0.637... | [0.5785123705863953, 0.6198347210884094, 0.661... | [0.6065573692321777, 0.6065573692321777, 0.606... | 18 | 1141 |
| 2 | selu | 109 | 0.253249 | 0.008099 | 64 | 21 | 0.786885 | 2 | 20.569868 | 22.421012 | [0.7877746224403381, 0.48364654183387756, 0.45... | [0.5014718770980835, 0.41901537775993347, 0.39... | [0.5330578684806824, 0.7520661354064941, 0.785... | [0.7704917788505554, 0.7868852615356445, 0.786... | 18 | 799 |
| 3 | sigmoid | 12 | 0.427878 | 0.001731 | 22 | 78 | 0.836066 | 3 | 22.447220 | 24.454956 | [0.6061558723449707, 0.550484836101532, 0.4878... | [0.4615059792995453, 0.41609662771224976, 0.39... | [0.6694214940071106, 0.6942148804664612, 0.772... | [0.7868852615356445, 0.7868852615356445, 0.770... | 18 | 2965 |
| 4 | sigmoid | 184 | 0.563842 | 0.000918 | 44 | 16 | 0.770492 | 4 | 24.481104 | 26.153962 | [0.7118028402328491, 0.6913579702377319, 0.675... | [0.6253404021263123, 0.6192606687545776, 0.613... | [0.56611567735672, 0.5826446413993835, 0.58264... | [0.7704917788505554, 0.7868852615356445, 0.786... | 18 | 609 |
| 5 | sigmoid | 22 | 0.392557 | 0.009368 | 41 | 53 | 0.786885 | 5 | 26.179926 | 28.258018 | [0.6151015758514404, 0.4353742301464081, 0.357... | [0.40750277042388916, 0.3809265196323395, 0.37... | [0.6528925895690918, 0.7933884263038635, 0.863... | [0.7868852615356445, 0.8360655903816223, 0.836... | 18 | 2015 |
| 6 | hard_sigmoid | 132 | 0.339039 | 0.000391 | 80 | 116 | 0.803279 | 6 | 28.283772 | 30.233132 | [1.384872317314148, 1.377575397491455, 1.33753... | [1.4819616079330444, 1.4416449069976807, 1.401... | [0.2851239740848541, 0.2851239740848541, 0.280... | [0.2295081913471222, 0.2295081913471222, 0.229... | 18 | 4409 |
| 7 | relu | 25 | 0.305810 | 0.000866 | 26 | 78 | 0.803279 | 7 | 30.259100 | 32.121436 | [0.7404576539993286, 0.6233335137367249, 0.549... | [0.6288543939590454, 0.5288269519805908, 0.462... | [0.5, 0.6859503984451294, 0.702479362487793, 0... | [0.6065573692321777, 0.7868852615356445, 0.852... | 18 | 2965 |
| 8 | softplus | 103 | 0.454461 | 0.000099 | 97 | 82 | 0.754098 | 8 | 32.147675 | 34.291445 | [0.6858380436897278, 0.6767894625663757, 0.682... | [0.5281822085380554, 0.5256621837615967, 0.523... | [0.6735537052154541, 0.6776859760284424, 0.677... | [0.7704917788505554, 0.7704917788505554, 0.770... | 18 | 3117 |
| 9 | softsign | 23 | 0.538048 | 0.003561 | 22 | 9 | 0.819672 | 9 | 34.317075 | 36.144872 | [0.6336663961410522, 0.5650404095649719, 0.526... | [0.5643037557601929, 0.4906170070171356, 0.446... | [0.64462810754776, 0.7190082669258118, 0.73966... | [0.7868852615356445, 0.7868852615356445, 0.819... | 18 | 343 |
| 10 | linear | 9 | 0.483396 | 0.000016 | 22 | 91 | 0.672131 | 10 | 36.253704 | 38.300674 | [0.8400824666023254, 0.8625382781028748, 0.812... | [0.8302125930786133, 0.8189805746078491, 0.807... | [0.39256197214126587, 0.41322314739227295, 0.4... | [0.3606557250022888, 0.39344263076782227, 0.40... | 18 | 3459 |
| 11 | hard_sigmoid | 9 | 0.435904 | 0.001394 | 19 | 85 | 0.852459 | 11 | 38.542972 | 40.685555 | [0.7858327627182007, 0.580945611000061, 0.5286... | [0.5257574319839478, 0.4599587619304657, 0.428... | [0.4586776793003082, 0.6859503984451294, 0.776... | [0.7704917788505554, 0.7868852615356445, 0.786... | 18 | 3231 |
| 12 | hard_sigmoid | 9 | 0.436711 | 0.000341 | 22 | 71 | 0.770492 | 12 | 40.800419 | 42.788335 | [0.6493225693702698, 0.6555594205856323, 0.620... | [0.5575143694877625, 0.5404179096221924, 0.523... | [0.6735537052154541, 0.6776859760284424, 0.702... | [0.7704917788505554, 0.7704917788505554, 0.770... | 18 | 2699 |
| 13 | gelu | 9 | 0.443914 | 0.004792 | 12 | 101 | 0.803279 | 13 | 42.902055 | 44.841357 | [0.48601630330085754, 0.3251952826976776, 0.29... | [0.36614474654197693, 0.4151676297187805, 0.40... | [0.7520661354064941, 0.8595041036605835, 0.867... | [0.8524590134620667, 0.8524590134620667, 0.836... | 18 | 3839 |
| 14 | linear | 11 | 0.459591 | 0.000904 | 11 | 83 | 0.836066 | 14 | 44.955593 | 46.634954 | [0.6354092955589294, 0.481924831867218, 0.3865... | [0.4674466848373413, 0.386948823928833, 0.3739... | [0.6115702390670776, 0.7479338645935059, 0.847... | [0.7868852615356445, 0.7868852615356445, 0.819... | 18 | 3155 |
| 15 | linear | 9 | 0.441282 | 0.000665 | 16 | 115 | 0.819672 | 15 | 46.749318 | 48.612520 | [0.7145628333091736, 0.504156231880188, 0.3972... | [0.5077534317970276, 0.3964807093143463, 0.371... | [0.5206611752510071, 0.7355371713638306, 0.826... | [0.7868852615356445, 0.8196721076965332, 0.819... | 18 | 4371 |
| 16 | hard_sigmoid | 9 | 0.590323 | 0.001896 | 22 | 92 | 0.852459 | 16 | 48.727985 | 50.911089 | [0.6284109354019165, 0.5719208121299744, 0.497... | [0.4557706415653229, 0.41930386424064636, 0.39... | [0.6404958963394165, 0.7190082669258118, 0.747... | [0.7704917788505554, 0.8360655903816223, 0.770... | 18 | 3497 |
| 17 | hard_sigmoid | 8 | 0.579865 | 0.001491 | 11 | 72 | 0.803279 | 17 | 51.027019 | 52.910879 | [0.6137444376945496, 0.5901528000831604, 0.506... | [0.47075191140174866, 0.4412596821784973, 0.41... | [0.702479362487793, 0.7148760557174683, 0.7314... | [0.7704917788505554, 0.7868852615356445, 0.786... | 18 | 2737 |
| 18 | gelu | 9 | 0.108936 | 0.001583 | 21 | 92 | 0.786885 | 18 | 53.027879 | 55.028541 | [0.5272975564002991, 0.3731013238430023, 0.328... | [0.40461263060569763, 0.3767029941082001, 0.38... | [0.7148760557174683, 0.8305785059928894, 0.851... | [0.7868852615356445, 0.8360655903816223, 0.836... | 18 | 3497 |
| 19 | tanh | 9 | 0.595015 | 0.001919 | 30 | 127 | 0.803279 | 19 | 55.145704 | 57.361813 | [0.5116466283798218, 0.35454192757606506, 0.33... | [0.36360660195350647, 0.3957943916320801, 0.40... | [0.7479338645935059, 0.8181818127632141, 0.842... | [0.8032786846160889, 0.8524590134620667, 0.836... | 18 | 4827 |
| 20 | hard_sigmoid | 10 | 0.596673 | 0.002164 | 74 | 80 | 0.819672 | 20 | 57.478000 | 60.821340 | [0.7859671115875244, 0.5692944526672363, 0.531... | [0.4949828088283539, 0.44248247146606445, 0.40... | [0.5041322112083435, 0.7231404781341553, 0.735... | [0.7704917788505554, 0.7868852615356445, 0.770... | 18 | 3041 |
| 21 | hard_sigmoid | 9 | 0.181801 | 0.001526 | 19 | 95 | 0.836066 | 21 | 60.939166 | 63.002136 | [0.6060517430305481, 0.535541832447052, 0.4644... | [0.48688802123069763, 0.4431024193763733, 0.41... | [0.6528925895690918, 0.7190082669258118, 0.785... | [0.7704917788505554, 0.7868852615356445, 0.786... | 18 | 3611 |
| 22 | hard_sigmoid | 10 | 0.550896 | 0.001073 | 26 | 85 | 0.836066 | 22 | 63.120133 | 65.200209 | [0.7356556057929993, 0.645238995552063, 0.5400... | [0.5445694923400879, 0.4956490695476532, 0.466... | [0.5206611752510071, 0.6570248007774353, 0.719... | [0.7704917788505554, 0.7704917788505554, 0.770... | 18 | 3231 |
| 23 | hard_sigmoid | 8 | 0.478580 | 0.001344 | 22 | 128 | 0.836066 | 23 | 65.413067 | 67.628386 | [0.6741029024124146, 0.5203006267547607, 0.471... | [0.46032172441482544, 0.41817986965179443, 0.3... | [0.6033057570457458, 0.7479338645935059, 0.764... | [0.7704917788505554, 0.8032786846160889, 0.770... | 18 | 4865 |
| 24 | linear | 9 | 0.390427 | 0.001105 | 18 | 60 | 0.819672 | 24 | 67.749137 | 69.669918 | [0.6414411664009094, 0.44960853457450867, 0.37... | [0.4244444668292999, 0.3778190612792969, 0.385... | [0.6115702390670776, 0.7851239442825317, 0.822... | [0.8196721076965332, 0.8032786846160889, 0.852... | 18 | 2281 |
The search can be continued without any issue.
[16]:
results = search.search(max_evals=5)
results
[16]:
| p:activation | p:batch_size | p:dropout_rate | p:learning_rate | p:num_epochs | p:units | objective | job_id | m:timestamp_submit | m:timestamp_gather | m:loss | m:val_loss | m:accuracy | m:val_accuracy | m:num_parameters | m:num_parameters_train | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | relu | 32 | 0.500000 | 0.001000 | 50 | 32 | 0.819672 | 0 | 14.062015 | 18.644915 | [0.932179868221283, 0.8672291040420532, 0.7659... | [0.8616852760314941, 0.7722538113594055, 0.698... | [0.3099173605442047, 0.35537189245224, 0.45041... | [0.32786884903907776, 0.39344263076782227, 0.5... | 18 | 1217 |
| 1 | tanh | 34 | 0.416012 | 0.000123 | 32 | 30 | 0.770492 | 1 | 18.689840 | 20.543970 | [0.7169904708862305, 0.7176796197891235, 0.672... | [0.6555299758911133, 0.6463007926940918, 0.637... | [0.5785123705863953, 0.6198347210884094, 0.661... | [0.6065573692321777, 0.6065573692321777, 0.606... | 18 | 1141 |
| 2 | selu | 109 | 0.253249 | 0.008099 | 64 | 21 | 0.786885 | 2 | 20.569868 | 22.421012 | [0.7877746224403381, 0.48364654183387756, 0.45... | [0.5014718770980835, 0.41901537775993347, 0.39... | [0.5330578684806824, 0.7520661354064941, 0.785... | [0.7704917788505554, 0.7868852615356445, 0.786... | 18 | 799 |
| 3 | sigmoid | 12 | 0.427878 | 0.001731 | 22 | 78 | 0.836066 | 3 | 22.447220 | 24.454956 | [0.6061558723449707, 0.550484836101532, 0.4878... | [0.4615059792995453, 0.41609662771224976, 0.39... | [0.6694214940071106, 0.6942148804664612, 0.772... | [0.7868852615356445, 0.7868852615356445, 0.770... | 18 | 2965 |
| 4 | sigmoid | 184 | 0.563842 | 0.000918 | 44 | 16 | 0.770492 | 4 | 24.481104 | 26.153962 | [0.7118028402328491, 0.6913579702377319, 0.675... | [0.6253404021263123, 0.6192606687545776, 0.613... | [0.56611567735672, 0.5826446413993835, 0.58264... | [0.7704917788505554, 0.7868852615356445, 0.786... | 18 | 609 |
| 5 | sigmoid | 22 | 0.392557 | 0.009368 | 41 | 53 | 0.786885 | 5 | 26.179926 | 28.258018 | [0.6151015758514404, 0.4353742301464081, 0.357... | [0.40750277042388916, 0.3809265196323395, 0.37... | [0.6528925895690918, 0.7933884263038635, 0.863... | [0.7868852615356445, 0.8360655903816223, 0.836... | 18 | 2015 |
| 6 | hard_sigmoid | 132 | 0.339039 | 0.000391 | 80 | 116 | 0.803279 | 6 | 28.283772 | 30.233132 | [1.384872317314148, 1.377575397491455, 1.33753... | [1.4819616079330444, 1.4416449069976807, 1.401... | [0.2851239740848541, 0.2851239740848541, 0.280... | [0.2295081913471222, 0.2295081913471222, 0.229... | 18 | 4409 |
| 7 | relu | 25 | 0.305810 | 0.000866 | 26 | 78 | 0.803279 | 7 | 30.259100 | 32.121436 | [0.7404576539993286, 0.6233335137367249, 0.549... | [0.6288543939590454, 0.5288269519805908, 0.462... | [0.5, 0.6859503984451294, 0.702479362487793, 0... | [0.6065573692321777, 0.7868852615356445, 0.852... | 18 | 2965 |
| 8 | softplus | 103 | 0.454461 | 0.000099 | 97 | 82 | 0.754098 | 8 | 32.147675 | 34.291445 | [0.6858380436897278, 0.6767894625663757, 0.682... | [0.5281822085380554, 0.5256621837615967, 0.523... | [0.6735537052154541, 0.6776859760284424, 0.677... | [0.7704917788505554, 0.7704917788505554, 0.770... | 18 | 3117 |
| 9 | softsign | 23 | 0.538048 | 0.003561 | 22 | 9 | 0.819672 | 9 | 34.317075 | 36.144872 | [0.6336663961410522, 0.5650404095649719, 0.526... | [0.5643037557601929, 0.4906170070171356, 0.446... | [0.64462810754776, 0.7190082669258118, 0.73966... | [0.7868852615356445, 0.7868852615356445, 0.819... | 18 | 343 |
| 10 | linear | 9 | 0.483396 | 0.000016 | 22 | 91 | 0.672131 | 10 | 36.253704 | 38.300674 | [0.8400824666023254, 0.8625382781028748, 0.812... | [0.8302125930786133, 0.8189805746078491, 0.807... | [0.39256197214126587, 0.41322314739227295, 0.4... | [0.3606557250022888, 0.39344263076782227, 0.40... | 18 | 3459 |
| 11 | hard_sigmoid | 9 | 0.435904 | 0.001394 | 19 | 85 | 0.852459 | 11 | 38.542972 | 40.685555 | [0.7858327627182007, 0.580945611000061, 0.5286... | [0.5257574319839478, 0.4599587619304657, 0.428... | [0.4586776793003082, 0.6859503984451294, 0.776... | [0.7704917788505554, 0.7868852615356445, 0.786... | 18 | 3231 |
| 12 | hard_sigmoid | 9 | 0.436711 | 0.000341 | 22 | 71 | 0.770492 | 12 | 40.800419 | 42.788335 | [0.6493225693702698, 0.6555594205856323, 0.620... | [0.5575143694877625, 0.5404179096221924, 0.523... | [0.6735537052154541, 0.6776859760284424, 0.702... | [0.7704917788505554, 0.7704917788505554, 0.770... | 18 | 2699 |
| 13 | gelu | 9 | 0.443914 | 0.004792 | 12 | 101 | 0.803279 | 13 | 42.902055 | 44.841357 | [0.48601630330085754, 0.3251952826976776, 0.29... | [0.36614474654197693, 0.4151676297187805, 0.40... | [0.7520661354064941, 0.8595041036605835, 0.867... | [0.8524590134620667, 0.8524590134620667, 0.836... | 18 | 3839 |
| 14 | linear | 11 | 0.459591 | 0.000904 | 11 | 83 | 0.836066 | 14 | 44.955593 | 46.634954 | [0.6354092955589294, 0.481924831867218, 0.3865... | [0.4674466848373413, 0.386948823928833, 0.3739... | [0.6115702390670776, 0.7479338645935059, 0.847... | [0.7868852615356445, 0.7868852615356445, 0.819... | 18 | 3155 |
| 15 | linear | 9 | 0.441282 | 0.000665 | 16 | 115 | 0.819672 | 15 | 46.749318 | 48.612520 | [0.7145628333091736, 0.504156231880188, 0.3972... | [0.5077534317970276, 0.3964807093143463, 0.371... | [0.5206611752510071, 0.7355371713638306, 0.826... | [0.7868852615356445, 0.8196721076965332, 0.819... | 18 | 4371 |
| 16 | hard_sigmoid | 9 | 0.590323 | 0.001896 | 22 | 92 | 0.852459 | 16 | 48.727985 | 50.911089 | [0.6284109354019165, 0.5719208121299744, 0.497... | [0.4557706415653229, 0.41930386424064636, 0.39... | [0.6404958963394165, 0.7190082669258118, 0.747... | [0.7704917788505554, 0.8360655903816223, 0.770... | 18 | 3497 |
| 17 | hard_sigmoid | 8 | 0.579865 | 0.001491 | 11 | 72 | 0.803279 | 17 | 51.027019 | 52.910879 | [0.6137444376945496, 0.5901528000831604, 0.506... | [0.47075191140174866, 0.4412596821784973, 0.41... | [0.702479362487793, 0.7148760557174683, 0.7314... | [0.7704917788505554, 0.7868852615356445, 0.786... | 18 | 2737 |
| 18 | gelu | 9 | 0.108936 | 0.001583 | 21 | 92 | 0.786885 | 18 | 53.027879 | 55.028541 | [0.5272975564002991, 0.3731013238430023, 0.328... | [0.40461263060569763, 0.3767029941082001, 0.38... | [0.7148760557174683, 0.8305785059928894, 0.851... | [0.7868852615356445, 0.8360655903816223, 0.836... | 18 | 3497 |
| 19 | tanh | 9 | 0.595015 | 0.001919 | 30 | 127 | 0.803279 | 19 | 55.145704 | 57.361813 | [0.5116466283798218, 0.35454192757606506, 0.33... | [0.36360660195350647, 0.3957943916320801, 0.40... | [0.7479338645935059, 0.8181818127632141, 0.842... | [0.8032786846160889, 0.8524590134620667, 0.836... | 18 | 4827 |
| 20 | hard_sigmoid | 10 | 0.596673 | 0.002164 | 74 | 80 | 0.819672 | 20 | 57.478000 | 60.821340 | [0.7859671115875244, 0.5692944526672363, 0.531... | [0.4949828088283539, 0.44248247146606445, 0.40... | [0.5041322112083435, 0.7231404781341553, 0.735... | [0.7704917788505554, 0.7868852615356445, 0.770... | 18 | 3041 |
| 21 | hard_sigmoid | 9 | 0.181801 | 0.001526 | 19 | 95 | 0.836066 | 21 | 60.939166 | 63.002136 | [0.6060517430305481, 0.535541832447052, 0.4644... | [0.48688802123069763, 0.4431024193763733, 0.41... | [0.6528925895690918, 0.7190082669258118, 0.785... | [0.7704917788505554, 0.7868852615356445, 0.786... | 18 | 3611 |
| 22 | hard_sigmoid | 10 | 0.550896 | 0.001073 | 26 | 85 | 0.836066 | 22 | 63.120133 | 65.200209 | [0.7356556057929993, 0.645238995552063, 0.5400... | [0.5445694923400879, 0.4956490695476532, 0.466... | [0.5206611752510071, 0.6570248007774353, 0.719... | [0.7704917788505554, 0.7704917788505554, 0.770... | 18 | 3231 |
| 23 | hard_sigmoid | 8 | 0.478580 | 0.001344 | 22 | 128 | 0.836066 | 23 | 65.413067 | 67.628386 | [0.6741029024124146, 0.5203006267547607, 0.471... | [0.46032172441482544, 0.41817986965179443, 0.3... | [0.6033057570457458, 0.7479338645935059, 0.764... | [0.7704917788505554, 0.8032786846160889, 0.770... | 18 | 4865 |
| 24 | linear | 9 | 0.390427 | 0.001105 | 18 | 60 | 0.819672 | 24 | 67.749137 | 69.669918 | [0.6414411664009094, 0.44960853457450867, 0.37... | [0.4244444668292999, 0.3778190612792969, 0.385... | [0.6115702390670776, 0.7851239442825317, 0.822... | [0.8196721076965332, 0.8032786846160889, 0.852... | 18 | 2281 |
| 25 | linear | 9 | 0.390427 | 0.001105 | 18 | 60 | 0.803279 | 25 | 76.058007 | 77.917548 | [0.6900577545166016, 0.45549991726875305, 0.38... | [0.44305503368377686, 0.375354528427124, 0.367... | [0.586776852607727, 0.7685950398445129, 0.8264... | [0.8032786846160889, 0.8032786846160889, 0.836... | 18 | 2281 |
| 26 | elu | 10 | 0.465738 | 0.001587 | 19 | 86 | 0.786885 | 26 | 78.044782 | 80.116082 | [0.5640519261360168, 0.39274558424949646, 0.35... | [0.36559411883354187, 0.36404427886009216, 0.3... | [0.7066115736961365, 0.8181818127632141, 0.826... | [0.8196721076965332, 0.8524590134620667, 0.852... | 18 | 3269 |
| 27 | hard_sigmoid | 11 | 0.558586 | 0.000470 | 16 | 97 | 0.770492 | 27 | 80.235434 | 82.186551 | [0.6638611555099487, 0.6282634139060974, 0.578... | [0.5112671256065369, 0.49481236934661865, 0.48... | [0.6900826692581177, 0.6900826692581177, 0.727... | [0.7704917788505554, 0.7704917788505554, 0.770... | 18 | 3687 |
| 28 | hard_sigmoid | 9 | 0.470758 | 0.001626 | 13 | 93 | 0.819672 | 28 | 82.308676 | 84.119199 | [0.6838790774345398, 0.5366182327270508, 0.500... | [0.4881541430950165, 0.44332659244537354, 0.41... | [0.6074380278587341, 0.7479338645935059, 0.752... | [0.7704917788505554, 0.7868852615356445, 0.836... | 18 | 3535 |
| 29 | hard_sigmoid | 14 | 0.443848 | 0.000821 | 18 | 91 | 0.868852 | 29 | 84.241275 | 86.165970 | [0.635932981967926, 0.5662679076194763, 0.5535... | [0.5330402851104736, 0.49324533343315125, 0.46... | [0.6528925895690918, 0.7231404781341553, 0.710... | [0.7704917788505554, 0.7704917788505554, 0.770... | 18 | 3459 |
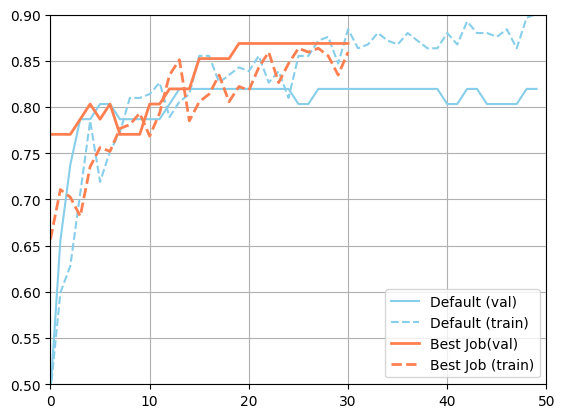
Now that the search is over, let us print the best configuration found during this run.
[17]:
i_max = results.objective.argmax()
best_job = results.iloc[i_max].to_dict()
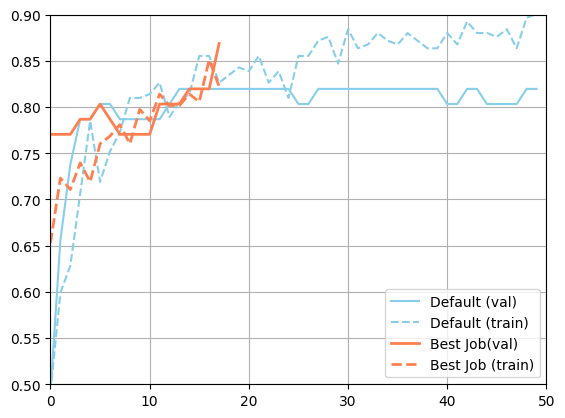
print(f"The default configuration has an accuracy of {objective_default:.3f}. \n"
f"The best configuration found by DeepHyper has an accuracy {results['objective'].iloc[i_max]:.3f}, \n"
f"discovered after {results['m:timestamp_gather'].iloc[i_max]:.2f} secondes of search.\n")
best_job
The default configuration has an accuracy of 0.820.
The best configuration found by DeepHyper has an accuracy 0.869,
discovered after 86.17 secondes of search.
[17]:
{'p:activation': 'hard_sigmoid',
'p:batch_size': 14,
'p:dropout_rate': 0.4438481734660434,
'p:learning_rate': 0.0008205301701702,
'p:num_epochs': 18,
'p:units': 91,
'objective': 0.868852436542511,
'job_id': 29,
'm:timestamp_submit': 84.2412748336792,
'm:timestamp_gather': 86.16596984863281,
'm:loss': '[0.635932981967926, 0.5662679076194763, 0.5535424947738647, 0.5280432105064392, 0.5272855162620544, 0.4944866895675659, 0.4731537699699402, 0.4632386565208435, 0.45537763833999634, 0.441008597612381, 0.43360987305641174, 0.41000625491142273, 0.3955390155315399, 0.3979620039463043, 0.4121660590171814, 0.3952913284301758, 0.37713170051574707, 0.37644729018211365]',
'm:val_loss': '[0.5330402851104736, 0.49324533343315125, 0.46836990118026733, 0.4523628056049347, 0.43521663546562195, 0.4218882620334625, 0.41329118609428406, 0.40013813972473145, 0.39292314648628235, 0.38573184609413147, 0.3782324492931366, 0.37434619665145874, 0.3733466863632202, 0.3698613941669464, 0.36946991086006165, 0.36632686853408813, 0.369396448135376, 0.37207305431365967]',
'm:accuracy': '[0.6528925895690918, 0.7231404781341553, 0.71074378490448, 0.7396694421768188, 0.7190082669258118, 0.7603305578231812, 0.7685950398445129, 0.7809917330741882, 0.7603305578231812, 0.797520637512207, 0.7851239442825317, 0.8140496015548706, 0.8016529083251953, 0.8016529083251953, 0.8140496015548706, 0.8057851195335388, 0.8512396812438965, 0.8223140239715576]',
'm:val_accuracy': '[0.7704917788505554, 0.7704917788505554, 0.7704917788505554, 0.7868852615356445, 0.7868852615356445, 0.8032786846160889, 0.7868852615356445, 0.7704917788505554, 0.7704917788505554, 0.7704917788505554, 0.7704917788505554, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.868852436542511]',
'm:num_parameters': 18,
'm:num_parameters_train': 3459}
[18]:
import matplotlib.pyplot as plt
plt.figure()
plt.plot(json.loads(metadata_default["val_accuracy"]), color="skyblue", label="Default (val)")
plt.plot(json.loads(metadata_default["accuracy"]), color="skyblue", linestyle="--", label="Default (train)")
plt.plot(json.loads(best_job["m:val_accuracy"]), color="coral", linewidth=2, label="Best Job(val)")
plt.plot(json.loads(best_job["m:accuracy"]), color="coral", linestyle="--", linewidth=2, label="Best Job (train)")
plt.legend()
plt.xlim(0,50)
plt.ylim(0.5, 0.9)
plt.grid()
plt.show()
2.9. Restart from a checkpoint#
It can often be useful to continue the search from previous results. For example, if the allocation requested was not enough or if an unexpected crash happened. The AMBS searhc provides the fit_surrogate(dataframe_of_results) method for this use case.
To simulate this we create a second evaluator evaluator_2 and start a fresh AMBS search with strong explotation kappa=0.001.
[19]:
# Create a new evaluator
evaluator_2 = get_evaluator(run)
# Create a new AMBS search with strong explotation (i.e., small kappa)
search_from_checkpoint = CBO(problem, evaluator_2, kappa=0.001)
# Initialize surrogate model of Bayesian optization
# With results of previous search
search_from_checkpoint.fit_surrogate(results)
Created new evaluator with 1 worker and config: {'num_cpus': 1, 'num_cpus_per_task': 1, 'callbacks': [<deephyper.evaluator.callback.TqdmCallback object at 0x36aa85450>]}
[20]:
results_from_checkpoint = search_from_checkpoint.search(max_evals=25)
[21]:
results_from_checkpoint
[21]:
| p:activation | p:batch_size | p:dropout_rate | p:learning_rate | p:num_epochs | p:units | objective | job_id | m:timestamp_submit | m:timestamp_gather | m:loss | m:val_loss | m:accuracy | m:val_accuracy | m:num_parameters | m:num_parameters_train | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | linear | 12 | 0.438976 | 0.001208 | 10 | 95 | 0.836066 | 0 | 6.397480 | 8.097164 | [0.6585780382156372, 0.4198558032512665, 0.388... | [0.4234312176704407, 0.3709704279899597, 0.375... | [0.586776852607727, 0.8223140239715576, 0.8181... | [0.8524590134620667, 0.8032786846160889, 0.852... | 18 | 3611 |
| 1 | hard_sigmoid | 12 | 0.520554 | 0.002753 | 24 | 86 | 0.836066 | 1 | 8.325622 | 10.485447 | [0.6523781418800354, 0.5374161005020142, 0.467... | [0.4600506126880646, 0.418490469455719, 0.3926... | [0.6322314143180847, 0.7355371713638306, 0.756... | [0.7704917788505554, 0.8032786846160889, 0.770... | 18 | 3269 |
| 2 | hard_sigmoid | 14 | 0.363236 | 0.001486 | 25 | 110 | 0.836066 | 2 | 10.607192 | 12.538232 | [0.8731681108474731, 0.5844830870628357, 0.526... | [0.5583247542381287, 0.463060587644577, 0.4330... | [0.39256197214126587, 0.7231404781341553, 0.71... | [0.7868852615356445, 0.7704917788505554, 0.786... | 18 | 4181 |
| 3 | selu | 14 | 0.460495 | 0.002067 | 12 | 83 | 0.819672 | 3 | 12.660986 | 14.445949 | [0.5941786766052246, 0.40573564171791077, 0.35... | [0.36787426471710205, 0.3851782977581024, 0.39... | [0.6900826692581177, 0.8140496015548706, 0.855... | [0.8196721076965332, 0.8360655903816223, 0.836... | 18 | 3155 |
| 4 | hard_sigmoid | 14 | 0.429233 | 0.001345 | 44 | 93 | 0.836066 | 4 | 14.567245 | 16.865442 | [0.8053226470947266, 0.5926507711410522, 0.555... | [0.5757733583450317, 0.4833868145942688, 0.449... | [0.4586776793003082, 0.7355371713638306, 0.719... | [0.7704917788505554, 0.7704917788505554, 0.770... | 18 | 3535 |
| 5 | hard_sigmoid | 12 | 0.435679 | 0.002768 | 19 | 98 | 0.852459 | 5 | 16.987307 | 18.849204 | [0.8416682481765747, 0.5458146333694458, 0.485... | [0.49310293793678284, 0.4248492121696472, 0.40... | [0.4834710657596588, 0.7190082669258118, 0.752... | [0.7704917788505554, 0.7868852615356445, 0.819... | 18 | 3725 |
| 6 | hard_sigmoid | 13 | 0.193879 | 0.002970 | 27 | 97 | 0.786885 | 6 | 18.970489 | 21.118783 | [0.6036434769630432, 0.4864918291568756, 0.419... | [0.44192907214164734, 0.39877942204475403, 0.3... | [0.6322314143180847, 0.7520661354064941, 0.814... | [0.7704917788505554, 0.7868852615356445, 0.803... | 18 | 3687 |
| 7 | hard_sigmoid | 12 | 0.398339 | 0.003165 | 16 | 86 | 0.803279 | 7 | 21.239853 | 23.158434 | [0.575615644454956, 0.4804820418357849, 0.4493... | [0.4336657226085663, 0.38864782452583313, 0.36... | [0.6983470916748047, 0.7520661354064941, 0.772... | [0.7868852615356445, 0.7704917788505554, 0.803... | 18 | 3269 |
| 8 | hard_sigmoid | 10 | 0.440850 | 0.001984 | 21 | 79 | 0.819672 | 8 | 23.280709 | 25.263713 | [0.6699650883674622, 0.5623903274536133, 0.494... | [0.4936249852180481, 0.43841785192489624, 0.40... | [0.5909090638160706, 0.702479362487793, 0.7685... | [0.7704917788505554, 0.7868852615356445, 0.786... | 18 | 3003 |
| 9 | selu | 12 | 0.477594 | 0.001919 | 24 | 112 | 0.803279 | 9 | 25.386227 | 27.457640 | [0.5322725176811218, 0.3245876729488373, 0.309... | [0.38319069147109985, 0.3997686803340912, 0.42... | [0.7231404781341553, 0.8429751992225647, 0.867... | [0.8032786846160889, 0.8360655903816223, 0.819... | 18 | 4257 |
| 10 | linear | 17 | 0.509973 | 0.002447 | 23 | 89 | 0.803279 | 10 | 27.581020 | 29.382152 | [0.5835959911346436, 0.37069475650787354, 0.33... | [0.3832534849643707, 0.3833093047142029, 0.397... | [0.6818181872367859, 0.8347107172012329, 0.871... | [0.8196721076965332, 0.8360655903816223, 0.852... | 18 | 3383 |
| 11 | hard_sigmoid | 15 | 0.523164 | 0.001067 | 54 | 85 | 0.836066 | 11 | 29.505811 | 32.134817 | [0.9218267798423767, 0.6668001413345337, 0.599... | [0.7107035517692566, 0.5423887968063354, 0.487... | [0.40909090638160706, 0.6074380278587341, 0.66... | [0.32786884903907776, 0.7868852615356445, 0.77... | 18 | 3231 |
| 12 | hard_sigmoid | 9 | 0.441817 | 0.001026 | 63 | 120 | 0.803279 | 12 | 32.257875 | 35.366201 | [0.6784322261810303, 0.593529462814331, 0.5153... | [0.512413740158081, 0.4700430631637573, 0.4388... | [0.702479362487793, 0.6942148804664612, 0.7685... | [0.7704917788505554, 0.7704917788505554, 0.786... | 18 | 4561 |
| 13 | hard_sigmoid | 12 | 0.544595 | 0.000872 | 31 | 108 | 0.868852 | 13 | 35.591719 | 37.863411 | [0.6894024014472961, 0.5956807136535645, 0.591... | [0.5160852670669556, 0.4825969934463501, 0.459... | [0.6570248007774353, 0.71074378490448, 0.70247... | [0.7704917788505554, 0.7704917788505554, 0.770... | 18 | 4105 |
| 14 | hard_sigmoid | 11 | 0.412163 | 0.000971 | 25 | 95 | 0.852459 | 14 | 37.986737 | 39.992904 | [0.6809544563293457, 0.5772911906242371, 0.549... | [0.5399053692817688, 0.4780106544494629, 0.451... | [0.56611567735672, 0.7272727489471436, 0.71074... | [0.7704917788505554, 0.7704917788505554, 0.770... | 18 | 3611 |
| 15 | hard_sigmoid | 9 | 0.529147 | 0.001269 | 21 | 104 | 0.819672 | 15 | 40.117375 | 42.095783 | [0.7127968668937683, 0.5936329960823059, 0.580... | [0.5231141448020935, 0.4680721163749695, 0.439... | [0.5619834661483765, 0.6942148804664612, 0.698... | [0.7704917788505554, 0.7704917788505554, 0.803... | 18 | 3953 |
| 16 | hard_sigmoid | 18 | 0.460586 | 0.000852 | 57 | 114 | 0.836066 | 16 | 42.219457 | 44.786083 | [0.620365560054779, 0.5650091767311096, 0.5926... | [0.5191843509674072, 0.4921819567680359, 0.471... | [0.6652892827987671, 0.702479362487793, 0.7024... | [0.7704917788505554, 0.7704917788505554, 0.770... | 18 | 4333 |
| 17 | hard_sigmoid | 11 | 0.387598 | 0.000823 | 36 | 107 | 0.852459 | 17 | 44.909478 | 47.169109 | [0.6506151556968689, 0.589153528213501, 0.5537... | [0.5208263993263245, 0.47787296772003174, 0.44... | [0.6694214940071106, 0.7272727489471436, 0.739... | [0.7704917788505554, 0.7704917788505554, 0.786... | 18 | 4067 |
| 18 | hard_sigmoid | 13 | 0.414306 | 0.001142 | 15 | 107 | 0.868852 | 18 | 47.295230 | 49.173612 | [0.6849047541618347, 0.6010968089103699, 0.530... | [0.5226393342018127, 0.4722970426082611, 0.444... | [0.5619834661483765, 0.7066115736961365, 0.743... | [0.7704917788505554, 0.7704917788505554, 0.786... | 18 | 4067 |
| 19 | hard_sigmoid | 18 | 0.486091 | 0.000940 | 16 | 98 | 0.803279 | 19 | 49.300318 | 51.107571 | [0.6370577216148376, 0.602827787399292, 0.5877... | [0.5238470435142517, 0.49890682101249695, 0.47... | [0.6652892827987671, 0.7148760557174683, 0.702... | [0.7704917788505554, 0.7704917788505554, 0.770... | 18 | 3725 |
| 20 | hard_sigmoid | 16 | 0.398807 | 0.000787 | 28 | 127 | 0.852459 | 20 | 51.235310 | 53.186919 | [0.690682590007782, 0.597438395023346, 0.54904... | [0.5534363985061646, 0.4879835247993469, 0.464... | [0.6115702390670776, 0.6776859760284424, 0.710... | [0.7704917788505554, 0.7704917788505554, 0.770... | 18 | 4827 |
| 21 | hard_sigmoid | 17 | 0.384646 | 0.000786 | 38 | 106 | 0.852459 | 21 | 53.313367 | 56.106235 | [0.6100438237190247, 0.5865045189857483, 0.532... | [0.5186737179756165, 0.4805293381214142, 0.459... | [0.6694214940071106, 0.6983470916748047, 0.739... | [0.7704917788505554, 0.7704917788505554, 0.770... | 18 | 4029 |
| 22 | hard_sigmoid | 14 | 0.356788 | 0.000776 | 36 | 93 | 0.852459 | 22 | 56.232855 | 58.367166 | [0.8494999408721924, 0.6852762699127197, 0.605... | [0.7045169472694397, 0.5688167214393616, 0.503... | [0.3677685856819153, 0.5165289044380188, 0.723... | [0.4590163826942444, 0.7704917788505554, 0.770... | 18 | 3535 |
| 23 | hard_sigmoid | 13 | 0.397346 | 0.001412 | 58 | 106 | 0.803279 | 23 | 58.493287 | 61.266117 | [0.5852853059768677, 0.5252292156219482, 0.463... | [0.47994744777679443, 0.4468657970428467, 0.41... | [0.6983470916748047, 0.7603305578231812, 0.752... | [0.7704917788505554, 0.7868852615356445, 0.819... | 18 | 4029 |
| 24 | hard_sigmoid | 11 | 0.592738 | 0.000858 | 36 | 102 | 0.852459 | 24 | 61.391166 | 63.710971 | [0.7020736932754517, 0.6323720216751099, 0.635... | [0.5165272355079651, 0.49130111932754517, 0.46... | [0.6652892827987671, 0.6942148804664612, 0.665... | [0.7704917788505554, 0.7704917788505554, 0.770... | 18 | 3877 |
[24]:
i_max = results_from_checkpoint.objective.argmax()
best_job = results_from_checkpoint.iloc[i_max].to_dict()
print(f"The default configuration has an accuracy of {objective_default:.3f}. \n"
f"The best configuration found by DeepHyper has an accuracy {results_from_checkpoint['objective'].iloc[i_max]:.3f}, \n"
f"discovered after {results_from_checkpoint['m:timestamp_gather'].iloc[i_max]:.2f} secondes of search.\n")
best_job
The default configuration has an accuracy of 0.820.
The best configuration found by DeepHyper has an accuracy 0.869,
discovered after 37.86 secondes of search.
[24]:
{'p:activation': 'hard_sigmoid',
'p:batch_size': 12,
'p:dropout_rate': 0.5445945061992221,
'p:learning_rate': 0.0008723159649302,
'p:num_epochs': 31,
'p:units': 108,
'objective': 0.868852436542511,
'job_id': 13,
'm:timestamp_submit': 35.591718912124634,
'm:timestamp_gather': 37.86341094970703,
'm:loss': '[0.6894024014472961, 0.5956807136535645, 0.5917392373085022, 0.5917980670928955, 0.5240165591239929, 0.5105810761451721, 0.48491740226745605, 0.4678659439086914, 0.4341070055961609, 0.44388189911842346, 0.46203067898750305, 0.4385513663291931, 0.373516708612442, 0.3806712031364441, 0.4247581362724304, 0.38694536685943604, 0.39678844809532166, 0.36177390813827515, 0.39248791337013245, 0.3694393038749695, 0.36910954117774963, 0.36527299880981445, 0.3246991038322449, 0.3702981472015381, 0.3380395472049713, 0.32118597626686096, 0.3399485945701599, 0.316026508808136, 0.3481677770614624, 0.332357257604599, 0.30446261167526245]',
'm:val_loss': '[0.5160852670669556, 0.4825969934463501, 0.4596042037010193, 0.4401782751083374, 0.4263782799243927, 0.40957772731781006, 0.39775389432907104, 0.3879868686199188, 0.3824841380119324, 0.37751471996307373, 0.3767043650150299, 0.37132832407951355, 0.36980336904525757, 0.36811932921409607, 0.36348962783813477, 0.3667713403701782, 0.3646043539047241, 0.36585021018981934, 0.3656473755836487, 0.3691723048686981, 0.3709169328212738, 0.3743424415588379, 0.37509554624557495, 0.3765678405761719, 0.38067683577537537, 0.3765696585178375, 0.38010162115097046, 0.38514068722724915, 0.3826046586036682, 0.38491377234458923, 0.39010316133499146]',
'm:accuracy': '[0.6570248007774353, 0.71074378490448, 0.702479362487793, 0.6818181872367859, 0.7355371713638306, 0.7561983466148376, 0.7520661354064941, 0.7768595218658447, 0.7809917330741882, 0.7933884263038635, 0.7685950398445129, 0.7933884263038635, 0.8347107172012329, 0.8512396812438965, 0.7851239442825317, 0.8057851195335388, 0.8140496015548706, 0.8347107172012329, 0.8057851195335388, 0.8223140239715576, 0.8181818127632141, 0.8429751992225647, 0.8595041036605835, 0.8264462947845459, 0.8471074104309082, 0.8636363744735718, 0.8595041036605835, 0.8636363744735718, 0.85537189245224, 0.8347107172012329, 0.8595041036605835]',
'm:val_accuracy': '[0.7704917788505554, 0.7704917788505554, 0.7704917788505554, 0.7868852615356445, 0.8032786846160889, 0.7868852615356445, 0.8032786846160889, 0.7704917788505554, 0.7704917788505554, 0.7704917788505554, 0.8032786846160889, 0.8032786846160889, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511]',
'm:num_parameters': 18,
'm:num_parameters_train': 4105}
[25]:
import matplotlib.pyplot as plt
plt.figure()
plt.plot(json.loads(metadata_default["val_accuracy"]), color="skyblue", label="Default (val)")
plt.plot(json.loads(metadata_default["accuracy"]), color="skyblue", linestyle="--", label="Default (train)")
plt.plot(json.loads(best_job["m:val_accuracy"]), color="coral", linewidth=2, label="Best Job(val)")
plt.plot(json.loads(best_job["m:accuracy"]), color="coral", linestyle="--", linewidth=2, label="Best Job (train)")
plt.legend()
plt.xlim(0,50)
plt.ylim(0.5, 0.9)
plt.grid()
plt.show()
2.10. Add conditional hyperparameters#
Now we want to add the possibility to search for a second fully-connected layer. We simply add two new lines:
if config.get("dense_2", False):
x = tf.keras.layers.Dense(config["dense_2:units"], activation=config["dense_2:activation"])(x)
[35]:
def run_with_condition(config: dict):
tf.autograph.set_verbosity(0)
train_dataframe, val_dataframe = load_data()
train_ds = dataframe_to_dataset(train_dataframe)
val_ds = dataframe_to_dataset(val_dataframe)
train_ds = train_ds.batch(config["batch_size"])
val_ds = val_ds.batch(config["batch_size"])
# Categorical features encoded as integers
sex = tf.keras.Input(shape=(1,), name="sex", dtype="int64")
cp = tf.keras.Input(shape=(1,), name="cp", dtype="int64")
fbs = tf.keras.Input(shape=(1,), name="fbs", dtype="int64")
restecg = tf.keras.Input(shape=(1,), name="restecg", dtype="int64")
exang = tf.keras.Input(shape=(1,), name="exang", dtype="int64")
ca = tf.keras.Input(shape=(1,), name="ca", dtype="int64")
# Categorical feature encoded as string
thal = tf.keras.Input(shape=(1,), name="thal", dtype="string")
# Numerical features
age = tf.keras.Input(shape=(1,), name="age")
trestbps = tf.keras.Input(shape=(1,), name="trestbps")
chol = tf.keras.Input(shape=(1,), name="chol")
thalach = tf.keras.Input(shape=(1,), name="thalach")
oldpeak = tf.keras.Input(shape=(1,), name="oldpeak")
slope = tf.keras.Input(shape=(1,), name="slope")
all_inputs = [
sex,
cp,
fbs,
restecg,
exang,
ca,
thal,
age,
trestbps,
chol,
thalach,
oldpeak,
slope,
]
# Integer categorical features
sex_encoded = encode_categorical_feature(sex, "sex", train_ds, False)
cp_encoded = encode_categorical_feature(cp, "cp", train_ds, False)
fbs_encoded = encode_categorical_feature(fbs, "fbs", train_ds, False)
restecg_encoded = encode_categorical_feature(restecg, "restecg", train_ds, False)
exang_encoded = encode_categorical_feature(exang, "exang", train_ds, False)
ca_encoded = encode_categorical_feature(ca, "ca", train_ds, False)
# String categorical features
thal_encoded = encode_categorical_feature(thal, "thal", train_ds, True)
# Numerical features
age_encoded = encode_numerical_feature(age, "age", train_ds)
trestbps_encoded = encode_numerical_feature(trestbps, "trestbps", train_ds)
chol_encoded = encode_numerical_feature(chol, "chol", train_ds)
thalach_encoded = encode_numerical_feature(thalach, "thalach", train_ds)
oldpeak_encoded = encode_numerical_feature(oldpeak, "oldpeak", train_ds)
slope_encoded = encode_numerical_feature(slope, "slope", train_ds)
all_features = tf.keras.layers.concatenate(
[
sex_encoded,
cp_encoded,
fbs_encoded,
restecg_encoded,
exang_encoded,
slope_encoded,
ca_encoded,
thal_encoded,
age_encoded,
trestbps_encoded,
chol_encoded,
thalach_encoded,
oldpeak_encoded,
]
)
x = tf.keras.layers.Dense(config["units"], activation=config["activation"])(
all_features
)
### START - NEW LINES
if config.get("dense_2", False):
x = tf.keras.layers.Dense(config["dense_2:units"], activation=config["dense_2:activation"])(x)
### END - NEW LINES
x = tf.keras.layers.Dropout(config["dropout_rate"])(x)
output = tf.keras.layers.Dense(1, activation="sigmoid")(x)
model = tf.keras.Model(all_inputs, output)
optimizer = tf.keras.optimizers.Adam(learning_rate=config["learning_rate"])
model.compile(optimizer, "binary_crossentropy", metrics=["accuracy"])
history = model.fit(
train_ds, epochs=config["num_epochs"], validation_data=val_ds, verbose=0
)
objective = history.history["val_accuracy"][-1]
metadata = {
"loss": history.history["loss"],
"val_loss": history.history["val_loss"],
"accuracy": history.history["accuracy"],
"val_accuracy": history.history["val_accuracy"],
}
metadata = {k:json.dumps(v) for k,v in metadata.items()}
metadata.update(count_params(model))
return {"objective": objective, "metadata": metadata}
To define conditionnal hyperparameters we use ConfigSpace. We define dense_2:units and dense_2:activation as active hyperparameters only when dense_2 == True. The cs.EqualsCondition help us do that. Then we call
problem_with_condition.add_condition(condition)
to register each new condition to the HpProblem.
[36]:
from deephyper.problem import EqualsCondition
# Define the hyperparameter problem
problem_with_condition = HpProblem()
# Define the same hyperparameters as before
problem_with_condition.add_hyperparameter((8, 128), "units")
problem_with_condition.add_hyperparameter(ACTIVATIONS, "activation")
problem_with_condition.add_hyperparameter((0.0, 0.6), "dropout_rate")
problem_with_condition.add_hyperparameter((10, 100), "num_epochs")
problem_with_condition.add_hyperparameter((8, 256, "log-uniform"), "batch_size")
problem_with_condition.add_hyperparameter((1e-5, 1e-2, "log-uniform"), "learning_rate")
# Add a new hyperparameter "dense_2 (bool)" to decide if a second fully-connected layer should be created
hp_dense_2 = problem_with_condition.add_hyperparameter([True, False], "dense_2")
hp_dense_2_units = problem_with_condition.add_hyperparameter((8, 128), "dense_2:units")
hp_dense_2_activation = problem_with_condition.add_hyperparameter(ACTIVATIONS, "dense_2:activation")
problem_with_condition.add_condition(EqualsCondition(hp_dense_2_units, hp_dense_2, True))
problem_with_condition.add_condition(EqualsCondition(hp_dense_2_activation, hp_dense_2, True))
problem_with_condition
[36]:
Configuration space object:
Hyperparameters:
activation, Type: Categorical, Choices: {elu, gelu, hard_sigmoid, linear, relu, selu, sigmoid, softplus, softsign, swish, tanh}, Default: elu
batch_size, Type: UniformInteger, Range: [8, 256], Default: 45, on log-scale
dense_2, Type: Categorical, Choices: {True, False}, Default: True
dense_2:activation, Type: Categorical, Choices: {elu, gelu, hard_sigmoid, linear, relu, selu, sigmoid, softplus, softsign, swish, tanh}, Default: elu
dense_2:units, Type: UniformInteger, Range: [8, 128], Default: 68
dropout_rate, Type: UniformFloat, Range: [0.0, 0.6], Default: 0.3
learning_rate, Type: UniformFloat, Range: [1e-05, 0.01], Default: 0.0003162278, on log-scale
num_epochs, Type: UniformInteger, Range: [10, 100], Default: 55
units, Type: UniformInteger, Range: [8, 128], Default: 68
Conditions:
dense_2:activation | dense_2 == True
dense_2:units | dense_2 == True
We create a new evaluator evaluator_3 and start a fresh AMBS search with this new problem problem_with_condition.
[37]:
evaluator_3 = get_evaluator(run_with_condition)
search_with_condition = CBO(problem_with_condition, evaluator_3)
Created new evaluator with 1 worker and config: {'num_cpus': 1, 'num_cpus_per_task': 1, 'callbacks': [<deephyper.evaluator.callback.TqdmCallback object at 0x36e9ecb50>]}
[38]:
results_with_condition = search_with_condition.search(max_evals=25)
[39]:
results_with_condition
[39]:
| p:activation | p:batch_size | p:dense_2 | p:dropout_rate | p:learning_rate | p:num_epochs | p:units | p:dense_2:activation | p:dense_2:units | objective | job_id | m:timestamp_submit | m:timestamp_gather | m:loss | m:val_loss | m:accuracy | m:val_accuracy | m:num_parameters | m:num_parameters_train | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | gelu | 24 | False | 0.522131 | 0.001057 | 44 | 8 | NaN | NaN | 0.819672 | 0 | 2.235576 | 4.550812 | [0.924185037612915, 0.8747961521148682, 0.8326... | [0.8763667941093445, 0.8163478970527649, 0.763... | [0.43801653385162354, 0.5123966932296753, 0.54... | [0.32786884903907776, 0.3606557250022888, 0.44... | 18 | 305 |
| 1 | softsign | 47 | True | 0.377181 | 0.000019 | 47 | 127 | elu | 75.0 | 0.819672 | 1 | 4.884659 | 6.967428 | [0.5733370184898376, 0.5688332319259644, 0.574... | [0.5401382446289062, 0.5361412763595581, 0.532... | [0.7148760557174683, 0.7396694421768188, 0.702... | [0.7377049326896667, 0.7540983557701111, 0.770... | 18 | 14375 |
| 2 | hard_sigmoid | 25 | False | 0.333931 | 0.000461 | 12 | 33 | NaN | NaN | 0.770492 | 2 | 7.296740 | 8.877128 | [0.6208266615867615, 0.6297191381454468, 0.623... | [0.5321816802024841, 0.5246576070785522, 0.517... | [0.7148760557174683, 0.7231404781341553, 0.706... | [0.7704917788505554, 0.7704917788505554, 0.770... | 18 | 1255 |
| 3 | softsign | 8 | True | 0.203617 | 0.000153 | 77 | 24 | softplus | 20.0 | 0.819672 | 3 | 9.212803 | 13.288342 | [1.1443312168121338, 1.0988541841506958, 0.993... | [1.1278998851776123, 1.0535285472869873, 0.983... | [0.2933884263038635, 0.27272728085517883, 0.30... | [0.2295081913471222, 0.2295081913471222, 0.229... | 18 | 1409 |
| 4 | tanh | 232 | False | 0.544339 | 0.000236 | 17 | 15 | NaN | NaN | 0.540984 | 4 | 13.726519 | 15.218855 | [0.8239354491233826, 0.8208498358726501, 0.838... | [0.7502322196960449, 0.7468000054359436, 0.743... | [0.4917355477809906, 0.44214877486228943, 0.47... | [0.49180328845977783, 0.49180328845977783, 0.4... | 18 | 571 |
| 5 | linear | 31 | True | 0.431446 | 0.002055 | 27 | 114 | tanh | 69.0 | 0.803279 | 5 | 15.547276 | 17.921458 | [0.512678325176239, 0.34136030077934265, 0.303... | [0.3721773326396942, 0.44410887360572815, 0.46... | [0.7148760557174683, 0.8512396812438965, 0.867... | [0.7868852615356445, 0.8524590134620667, 0.836... | 18 | 12223 |
| 6 | swish | 185 | True | 0.143728 | 0.000066 | 36 | 126 | relu | 88.0 | 0.786885 | 6 | 18.249087 | 19.944625 | [0.7136270403862, 0.7156499624252319, 0.704962... | [0.7125016450881958, 0.7087024450302124, 0.704... | [0.3677685856819153, 0.40909090638160706, 0.47... | [0.4590163826942444, 0.49180328845977783, 0.50... | 18 | 15927 |
| 7 | selu | 85 | True | 0.513058 | 0.000975 | 20 | 24 | elu | 77.0 | 0.819672 | 7 | 20.271154 | 21.969523 | [0.5428742170333862, 0.5066077709197998, 0.472... | [0.5021791458129883, 0.4607888162136078, 0.434... | [0.7520661354064941, 0.7355371713638306, 0.772... | [0.8032786846160889, 0.8196721076965332, 0.803... | 18 | 2891 |
| 8 | softplus | 256 | False | 0.541869 | 0.000032 | 44 | 123 | NaN | NaN | 0.737705 | 8 | 22.299193 | 24.046926 | [0.8337835669517517, 0.7673187255859375, 0.769... | [0.6750521063804626, 0.6737582087516785, 0.672... | [0.5330578684806824, 0.5413222908973694, 0.520... | [0.6557376980781555, 0.6557376980781555, 0.672... | 18 | 4675 |
| 9 | hard_sigmoid | 57 | True | 0.221024 | 0.000014 | 77 | 101 | selu | 56.0 | 0.770492 | 9 | 24.373393 | 26.569876 | [1.2874423265457153, 1.2473254203796387, 1.279... | [1.334114909172058, 1.3099576234817505, 1.2861... | [0.2851239740848541, 0.28925618529319763, 0.28... | [0.2295081913471222, 0.2295081913471222, 0.229... | 18 | 9506 |
| 10 | gelu | 18 | False | 0.564763 | 0.000933 | 54 | 15 | NaN | NaN | 0.819672 | 10 | 27.104312 | 29.572576 | [0.5897572636604309, 0.57463538646698, 0.57585... | [0.5318115949630737, 0.5115801095962524, 0.493... | [0.6859503984451294, 0.6776859760284424, 0.710... | [0.7868852615356445, 0.7868852615356445, 0.803... | 18 | 571 |
| 11 | gelu | 142 | False | 0.579399 | 0.001457 | 89 | 25 | NaN | NaN | 0.819672 | 11 | 30.006772 | 32.050175 | [0.7384172081947327, 0.7030460834503174, 0.697... | [0.7297533750534058, 0.7030223608016968, 0.677... | [0.5619834661483765, 0.5743801593780518, 0.561... | [0.5737704634666443, 0.6229507923126221, 0.655... | 18 | 951 |
| 12 | gelu | 134 | False | 0.559896 | 0.000204 | 18 | 20 | NaN | NaN | 0.557377 | 12 | 32.490820 | 34.208299 | [0.7932754158973694, 0.8488675951957703, 0.829... | [0.7328909039497375, 0.7296200394630432, 0.726... | [0.4752066135406494, 0.42561984062194824, 0.41... | [0.49180328845977783, 0.5081967115402222, 0.50... | 18 | 761 |
| 13 | gelu | 242 | False | 0.515215 | 0.002007 | 75 | 35 | NaN | NaN | 0.852459 | 13 | 34.639509 | 36.527177 | [0.859049379825592, 0.8296051025390625, 0.8243... | [0.7826507687568665, 0.7542334794998169, 0.727... | [0.40082645416259766, 0.44214877486228943, 0.3... | [0.3442623019218445, 0.4098360538482666, 0.459... | 18 | 1331 |
| 14 | gelu | 226 | False | 0.031790 | 0.007343 | 58 | 40 | NaN | NaN | 0.770492 | 14 | 36.960484 | 38.937768 | [0.7312912940979004, 0.5623873472213745, 0.466... | [0.5508450269699097, 0.44452348351478577, 0.39... | [0.42561984062194824, 0.7851239442825317, 0.80... | [0.7704917788505554, 0.8196721076965332, 0.803... | 18 | 1521 |
| 15 | softplus | 203 | False | 0.554349 | 0.003512 | 93 | 37 | NaN | NaN | 0.819672 | 15 | 39.373037 | 41.404819 | [1.0284086465835571, 0.9733473658561707, 0.859... | [0.8921995162963867, 0.7531617879867554, 0.649... | [0.41322314739227295, 0.43388429284095764, 0.5... | [0.24590164422988892, 0.3442623019218445, 0.62... | 18 | 1407 |
| 16 | gelu | 232 | False | 0.362360 | 0.001611 | 74 | 51 | NaN | NaN | 0.836066 | 16 | 41.948220 | 44.062609 | [0.7161883115768433, 0.6824987530708313, 0.680... | [0.6093551516532898, 0.5813453197479248, 0.557... | [0.5413222908973694, 0.5785123705863953, 0.607... | [0.688524603843689, 0.7049180269241333, 0.7049... | 18 | 1939 |
| 17 | gelu | 234 | False | 0.494525 | 0.000187 | 81 | 34 | NaN | NaN | 0.786885 | 17 | 44.499486 | 46.484084 | [0.6872013807296753, 0.6597692966461182, 0.683... | [0.6522549986839294, 0.6491743326187134, 0.646... | [0.5619834661483765, 0.6033057570457458, 0.541... | [0.7213114500045776, 0.7377049326896667, 0.737... | 18 | 1293 |
| 18 | gelu | 197 | False | 0.260730 | 0.002156 | 72 | 65 | NaN | NaN | 0.786885 | 18 | 46.924379 | 49.068913 | [0.7648653388023376, 0.702664315700531, 0.6466... | [0.6779869198799133, 0.62514728307724, 0.57954... | [0.43801653385162354, 0.586776852607727, 0.636... | [0.6393442749977112, 0.688524603843689, 0.7540... | 18 | 2471 |
| 19 | tanh | 253 | False | 0.387836 | 0.005233 | 100 | 44 | NaN | NaN | 0.803279 | 19 | 49.509489 | 51.511528 | [0.9511580467224121, 0.8183630108833313, 0.676... | [0.8083988428115845, 0.6910563111305237, 0.599... | [0.37603306770324707, 0.42561984062194824, 0.5... | [0.4262295067310333, 0.5573770403862, 0.688524... | 18 | 1673 |
| 20 | gelu | 215 | False | 0.496468 | 0.000754 | 62 | 52 | NaN | NaN | 0.819672 | 20 | 51.948622 | 53.995673 | [0.6701352596282959, 0.630990743637085, 0.6785... | [0.614578127861023, 0.6000330448150635, 0.5868... | [0.6611570119857788, 0.702479362487793, 0.6198... | [0.7540983557701111, 0.7540983557701111, 0.770... | 18 | 1977 |
| 21 | gelu | 216 | False | 0.506153 | 0.001577 | 31 | 123 | NaN | NaN | 0.852459 | 21 | 54.549624 | 56.165359 | [0.7263947129249573, 0.6771824955940247, 0.611... | [0.6366023421287537, 0.5854663252830505, 0.541... | [0.4628099203109741, 0.5619834661483765, 0.706... | [0.7704917788505554, 0.8032786846160889, 0.803... | 18 | 4675 |
| 22 | gelu | 13 | False | 0.506717 | 0.006827 | 37 | 122 | NaN | NaN | 0.803279 | 22 | 56.607589 | 58.999443 | [0.4278903603553772, 0.3155879080295563, 0.283... | [0.4139474332332611, 0.45352885127067566, 0.43... | [0.8057851195335388, 0.8719007968902588, 0.892... | [0.7868852615356445, 0.7868852615356445, 0.803... | 18 | 4637 |
| 23 | gelu | 218 | False | 0.496672 | 0.002579 | 35 | 95 | NaN | NaN | 0.803279 | 23 | 59.442295 | 61.092887 | [0.6519522070884705, 0.5893392562866211, 0.535... | [0.5795789957046509, 0.5213544368743896, 0.478... | [0.6280992031097412, 0.7355371713638306, 0.768... | [0.7868852615356445, 0.8032786846160889, 0.819... | 18 | 3611 |
| 24 | gelu | 102 | True | 0.564560 | 0.001154 | 22 | 121 | swish | 58.0 | 0.836066 | 24 | 61.534962 | 63.325902 | [0.6295450329780579, 0.5699268579483032, 0.503... | [0.5654922127723694, 0.5030131936073303, 0.457... | [0.6776859760284424, 0.7190082669258118, 0.760... | [0.8032786846160889, 0.8032786846160889, 0.819... | 18 | 11612 |
Finally, let us print out the best configuration found from this conditionned search space.
[41]:
i_max = results_with_condition.objective.argmax()
best_job = results_with_condition.iloc[i_max].to_dict()
print(f"The default configuration has an accuracy of {objective_default:.3f}. \n"
f"The best configuration found by DeepHyper has an accuracy {results_with_condition['objective'].iloc[i_max]:.3f}, \n"
f"discovered after {results_with_condition['m:timestamp_gather'].iloc[i_max]:.2f} secondes of search.\n")
best_job
The default configuration has an accuracy of 0.820.
The best configuration found by DeepHyper has an accuracy 0.852,
discovered after 36.53 secondes of search.
[41]:
{'p:activation': 'gelu',
'p:batch_size': 242,
'p:dense_2': False,
'p:dropout_rate': 0.5152152399825081,
'p:learning_rate': 0.0020066536451654,
'p:num_epochs': 75,
'p:units': 35,
'p:dense_2:activation': nan,
'p:dense_2:units': nan,
'objective': 0.8524590134620667,
'job_id': 13,
'm:timestamp_submit': 34.639508962631226,
'm:timestamp_gather': 36.52717709541321,
'm:loss': '[0.859049379825592, 0.8296051025390625, 0.8243043422698975, 0.7973544597625732, 0.7397300004959106, 0.7041493654251099, 0.7235077619552612, 0.6488988995552063, 0.702877402305603, 0.6625365018844604, 0.655247151851654, 0.6482662558555603, 0.6332350373268127, 0.5944415926933289, 0.599096953868866, 0.5725361704826355, 0.5635514259338379, 0.5673025250434875, 0.5335801839828491, 0.5114941000938416, 0.5681918859481812, 0.5181658864021301, 0.5367188453674316, 0.4979115426540375, 0.4959726631641388, 0.4972151219844818, 0.49240514636039734, 0.4656968414783478, 0.46458086371421814, 0.47685131430625916, 0.4619789123535156, 0.42305096983909607, 0.4502629041671753, 0.45318228006362915, 0.4273068904876709, 0.45731934905052185, 0.4358069598674774, 0.4073839485645294, 0.40324676036834717, 0.39515185356140137, 0.3967740535736084, 0.42188364267349243, 0.3988163471221924, 0.414568156003952, 0.38948333263397217, 0.3933953642845154, 0.3803653120994568, 0.4041972756385803, 0.38209018111228943, 0.37077051401138306, 0.3959812521934509, 0.3823794722557068, 0.37696704268455505, 0.38598284125328064, 0.37342891097068787, 0.36935892701148987, 0.3629962205886841, 0.3568687438964844, 0.35987207293510437, 0.35740146040916443, 0.3505695164203644, 0.3561004102230072, 0.3582131266593933, 0.37328383326530457, 0.3326776325702667, 0.34751608967781067, 0.34388142824172974, 0.32585853338241577, 0.34427350759506226, 0.3316827714443207, 0.3136938512325287, 0.34206631779670715, 0.3135722279548645, 0.3292677700519562, 0.3271864652633667]',
'm:val_loss': '[0.7826507687568665, 0.7542334794998169, 0.7272999286651611, 0.7016635537147522, 0.6774805188179016, 0.6546944379806519, 0.6334282159805298, 0.6135805249214172, 0.5949371457099915, 0.5774815678596497, 0.5610758066177368, 0.5457151532173157, 0.5314500331878662, 0.5182359218597412, 0.5059540867805481, 0.49457502365112305, 0.48407983779907227, 0.47442489862442017, 0.46552494168281555, 0.4573885202407837, 0.44996970891952515, 0.44316211342811584, 0.4370157718658447, 0.43129366636276245, 0.4260532855987549, 0.42123591899871826, 0.41692915558815, 0.4130058288574219, 0.4093940854072571, 0.40622448921203613, 0.40338370203971863, 0.4008386433124542, 0.3985663056373596, 0.3966066539287567, 0.3948517143726349, 0.39329880475997925, 0.39195170998573303, 0.390933632850647, 0.3902509808540344, 0.38974982500076294, 0.3894272744655609, 0.38932961225509644, 0.38939112424850464, 0.38970157504081726, 0.38995805382728577, 0.39017829298973083, 0.3904784023761749, 0.3908677101135254, 0.3912723660469055, 0.39176133275032043, 0.3920464813709259, 0.3923230767250061, 0.3927132785320282, 0.39302974939346313, 0.39317506551742554, 0.39328402280807495, 0.393261194229126, 0.39328503608703613, 0.3932672441005707, 0.39302825927734375, 0.39276590943336487, 0.39265578985214233, 0.3927079439163208, 0.3927791118621826, 0.39287132024765015, 0.3929784595966339, 0.39310818910598755, 0.3932960033416748, 0.3935457170009613, 0.39387473464012146, 0.3941606879234314, 0.3945646584033966, 0.3948483169078827, 0.39523547887802124, 0.39547473192214966]',
'm:accuracy': '[0.40082645416259766, 0.44214877486228943, 0.39256197214126587, 0.41735535860061646, 0.4958677589893341, 0.5, 0.5123966932296753, 0.6157024502754211, 0.5785123705863953, 0.6198347210884094, 0.6033057570457458, 0.6280992031097412, 0.6239669322967529, 0.6983470916748047, 0.6570248007774353, 0.71074378490448, 0.71074378490448, 0.7148760557174683, 0.7190082669258118, 0.7355371713638306, 0.7148760557174683, 0.7479338645935059, 0.7355371713638306, 0.7809917330741882, 0.7727272510528564, 0.7561983466148376, 0.7520661354064941, 0.7933884263038635, 0.7727272510528564, 0.797520637512207, 0.8016529083251953, 0.85537189245224, 0.797520637512207, 0.8099173307418823, 0.8223140239715576, 0.797520637512207, 0.8512396812438965, 0.8347107172012329, 0.8305785059928894, 0.8305785059928894, 0.8429751992225647, 0.8223140239715576, 0.8223140239715576, 0.8057851195335388, 0.8264462947845459, 0.8388429880142212, 0.8347107172012329, 0.8305785059928894, 0.8429751992225647, 0.8595041036605835, 0.8305785059928894, 0.8388429880142212, 0.8305785059928894, 0.8140496015548706, 0.8512396812438965, 0.8305785059928894, 0.8471074104309082, 0.8388429880142212, 0.8388429880142212, 0.8429751992225647, 0.8636363744735718, 0.8429751992225647, 0.8388429880142212, 0.8636363744735718, 0.8677685856819153, 0.85537189245224, 0.8636363744735718, 0.8760330677032471, 0.8512396812438965, 0.8595041036605835, 0.8636363744735718, 0.8636363744735718, 0.8471074104309082, 0.8595041036605835, 0.85537189245224]',
'm:val_accuracy': '[0.3442623019218445, 0.4098360538482666, 0.4590163826942444, 0.4754098355770111, 0.5245901346206665, 0.5409836173057556, 0.6393442749977112, 0.7213114500045776, 0.7377049326896667, 0.7704917788505554, 0.8032786846160889, 0.8032786846160889, 0.8196721076965332, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667]',
'm:num_parameters': 18,
'm:num_parameters_train': 1331}
[42]:
import matplotlib.pyplot as plt
plt.figure()
plt.plot(json.loads(metadata_default["val_accuracy"]), color="skyblue", label="Default (val)")
plt.plot(json.loads(metadata_default["accuracy"]), color="skyblue", linestyle="--", label="Default (train)")
plt.plot(json.loads(best_job["m:val_accuracy"]), color="coral", linewidth=2, label="Best Job(val)")
plt.plot(json.loads(best_job["m:accuracy"]), color="coral", linestyle="--", linewidth=2, label="Best Job (train)")
plt.legend()
plt.xlim(0,50)
plt.ylim(0.5, 0.9)
plt.grid()
plt.show()
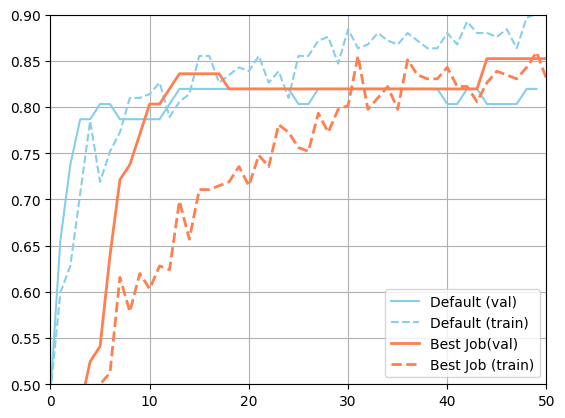
[ ]: