
3. Multi-Fidelity Hyperparameter Optimization with Keras#
![]()
In this tutorial we present how to use hyperparameter optimization on a basic example from the Keras documentation. We follow the previous tutorial based on the same example and add multi-fidelity to it. The purpose of multi-fidelity is to dynamically manage the budget allocated (also called fidelity) to evaluate an hyperparameter configuration. For example, when training a deep neural network the number of epochs can be continued or stopped based on currently observed performance and some policy.
In DeepHyper, the multi-fidelity agent is designed separately from the hyperparameter search agent. Of course, both can communicate but from an API perspective they are different objects. The multi-fidelity agents are called Stopper in DeepHyper and their documentation can be found at deephyper.stopper.
In this notebook, we will demonstrate how to use multi-fidelity inside sequential Bayesian optimization. When moving to a distributed setting, it is important to use a shared database accessible by all workers otherwise the multi-fidelity scheme may not work properly. An example, of database instanciation for parallel computing is explained in: Introduction to Distributed Bayesian Optimization (DBO) with MPI (Communication) and Redis (Storage).
Reference: This tutorial is based on materials from the Keras Documentation: Structured data classification from scratch
Let us start with installing DeepHyper!
Warning
This tutorial should be run with tensorflow>=2.6.
[1]:
# !pip install "deephyper[jax-cpu]"
import deephyper
print(deephyper.__version__)
0.6.0
Note
The following environment variables can be used to avoid the logging of some Tensorflow DEBUG, INFO and WARNING statements.
[2]:
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = str(4)
os.environ["AUTOGRAPH_VERBOSITY"] = str(0)
3.1. Imports#
[3]:
import pandas as pd
import tensorflow as tf
tf.get_logger().setLevel("ERROR")
3.2. The dataset (from Keras.io)#
The dataset is provided by the Cleveland Clinic Foundation for Heart Disease. It’s a CSV file with 303 rows. Each row contains information about a patient (a sample), and each column describes an attribute of the patient (a feature). We use the features to predict whether a patient has a heart disease (binary classification).
Here’s the description of each feature:
Column |
Description |
Feature Type |
|---|---|---|
Age |
Age in years |
Numerical |
Sex |
(1 = male; 0 = female) |
Categorical |
CP |
Chest pain type (0, 1, 2, 3, 4) |
Categorical |
Trestbpd |
Resting blood pressure (in mm Hg on admission) |
Numerical |
Chol |
Serum cholesterol in mg/dl |
Numerical |
FBS |
fasting blood sugar in 120 mg/dl (1 = true; 0 = false) |
Categorical |
RestECG |
Resting electrocardiogram results (0, 1, 2) |
Categorical |
Thalach |
Maximum heart rate achieved |
Numerical |
Exang |
Exercise induced angina (1 = yes; 0 = no) |
Categorical |
Oldpeak |
ST depression induced by exercise relative to rest |
Numerical |
Slope |
Slope of the peak exercise ST segment |
Numerical |
CA |
Number of major vessels (0-3) colored by fluoroscopy |
Both numerical & categorical |
Thal |
3 = normal; 6 = fixed defect; 7 = reversible defect |
Categorical |
Target |
Diagnosis of heart disease (1 = true; 0 = false) |
Target |
[4]:
def load_data():
file_url = "http://storage.googleapis.com/download.tensorflow.org/data/heart.csv"
dataframe = pd.read_csv(file_url)
val_dataframe = dataframe.sample(frac=0.2, random_state=1337)
train_dataframe = dataframe.drop(val_dataframe.index)
return train_dataframe, val_dataframe
def dataframe_to_dataset(dataframe):
dataframe = dataframe.copy()
labels = dataframe.pop("target")
ds = tf.data.Dataset.from_tensor_slices((dict(dataframe), labels))
ds = ds.shuffle(buffer_size=len(dataframe))
return ds
3.3. Preprocessing & encoding of features#
The next cells use tf.keras.layers.Normalization() to apply standard scaling on the features.
Then, the tf.keras.layers.StringLookup and tf.keras.layers.IntegerLookup are used to encode categorical variables.
[5]:
def encode_numerical_feature(feature, name, dataset):
# Create a Normalization layer for our feature
normalizer = tf.keras.layers.Normalization()
# Prepare a Dataset that only yields our feature
feature_ds = dataset.map(lambda x, y: x[name])
feature_ds = feature_ds.map(lambda x: tf.expand_dims(x, -1))
# Learn the statistics of the data
normalizer.adapt(feature_ds)
# Normalize the input feature
encoded_feature = normalizer(feature)
return encoded_feature
def encode_categorical_feature(feature, name, dataset, is_string):
lookup_class = (
tf.keras.layers.StringLookup if is_string else tf.keras.layers.IntegerLookup
)
# Create a lookup layer which will turn strings into integer indices
lookup = lookup_class(output_mode="binary")
# Prepare a Dataset that only yields our feature
feature_ds = dataset.map(lambda x, y: x[name])
feature_ds = feature_ds.map(lambda x: tf.expand_dims(x, -1))
# Learn the set of possible string values and assign them a fixed integer index
lookup.adapt(feature_ds)
# Turn the string input into integer indices
encoded_feature = lookup(feature)
return encoded_feature
3.4. Define the run-function with multi-fidelity#
The run-function defines how the objective that we want to maximize is computed. It takes a job (see deephyper.evaluator.RunningJob) as input and outputs a scaler value or dictionnary (see deephyper.evaluator). The objective is always maximized in DeepHyper. The job.parameters contains a suggested
configuration of hyperparameters that we want to evaluate. In this example we will search for:
units(default value:32)activation(default value:"relu")dropout_rate(default value:0.5)batch_size(default value:32)learning_rate(default value:1e-3)
A hyperparameter value can be acessed easily in the dictionary through the corresponding key, for example job["units"] or job.parameters["units"] are both valid. Unlike the previous tutorial in this example we want to use multi-fidelity to dynamically choose the allocated budget of each evaluation. Therefore we use the tensorflow keras integration of stoppers deephyper.stopper.integration.TFKerasStopperCallback. The multi-fidelity agent will monitor the validation accuracy
(val_accuracy) in the context of maximization. This stopper_callback is then added to the callbacks used by the model during the training. In order to collect more information about the execution of our job we use the @profile decorator on the run-function which will collect execution timings (timestamp_start and timestamp_end). We will also add "metadata" to the output of our function to know how many epochs were used to evaluate each model. To learn more about how the
@profile decorator can be used check our tutorial on Understanding the pros and cons of Evaluator parallel backends.
stopper_callback = TFKerasStopperCallback(
job,
monitor="val_accuracy",
mode="max"
)
history = model.fit(
train_ds,
epochs=100,
validation_data=val_ds,
verbose=0,
callbacks=[stopper_callback]
)
objective = history.history["val_accuracy"][-1]
metadata = {"budget": stopper_callback.budget}
return {"objective": objective, "metadata": metadata}
[15]:
import json
from deephyper.evaluator import profile, RunningJob
from deephyper.stopper.integration.tensorflow import TFKerasStopperCallback
@profile
def run(job):
config = job.parameters
tf.autograph.set_verbosity(0)
import absl.logging
absl.logging.set_verbosity(absl.logging.ERROR)
# Load data and split into validation set
train_dataframe, val_dataframe = load_data()
train_ds = dataframe_to_dataset(train_dataframe)
val_ds = dataframe_to_dataset(val_dataframe)
train_ds = train_ds.batch(config["batch_size"])
val_ds = val_ds.batch(config["batch_size"])
# Categorical features encoded as integers
sex = tf.keras.Input(shape=(1,), name="sex", dtype="int64")
cp = tf.keras.Input(shape=(1,), name="cp", dtype="int64")
fbs = tf.keras.Input(shape=(1,), name="fbs", dtype="int64")
restecg = tf.keras.Input(shape=(1,), name="restecg", dtype="int64")
exang = tf.keras.Input(shape=(1,), name="exang", dtype="int64")
ca = tf.keras.Input(shape=(1,), name="ca", dtype="int64")
# Categorical feature encoded as string
thal = tf.keras.Input(shape=(1,), name="thal", dtype="string")
# Numerical features
age = tf.keras.Input(shape=(1,), name="age")
trestbps = tf.keras.Input(shape=(1,), name="trestbps")
chol = tf.keras.Input(shape=(1,), name="chol")
thalach = tf.keras.Input(shape=(1,), name="thalach")
oldpeak = tf.keras.Input(shape=(1,), name="oldpeak")
slope = tf.keras.Input(shape=(1,), name="slope")
all_inputs = [
sex,
cp,
fbs,
restecg,
exang,
ca,
thal,
age,
trestbps,
chol,
thalach,
oldpeak,
slope,
]
# Integer categorical features
sex_encoded = encode_categorical_feature(sex, "sex", train_ds, False)
cp_encoded = encode_categorical_feature(cp, "cp", train_ds, False)
fbs_encoded = encode_categorical_feature(fbs, "fbs", train_ds, False)
restecg_encoded = encode_categorical_feature(restecg, "restecg", train_ds, False)
exang_encoded = encode_categorical_feature(exang, "exang", train_ds, False)
ca_encoded = encode_categorical_feature(ca, "ca", train_ds, False)
# String categorical features
thal_encoded = encode_categorical_feature(thal, "thal", train_ds, True)
# Numerical features
age_encoded = encode_numerical_feature(age, "age", train_ds)
trestbps_encoded = encode_numerical_feature(trestbps, "trestbps", train_ds)
chol_encoded = encode_numerical_feature(chol, "chol", train_ds)
thalach_encoded = encode_numerical_feature(thalach, "thalach", train_ds)
oldpeak_encoded = encode_numerical_feature(oldpeak, "oldpeak", train_ds)
slope_encoded = encode_numerical_feature(slope, "slope", train_ds)
all_features = tf.keras.layers.concatenate(
[
sex_encoded,
cp_encoded,
fbs_encoded,
restecg_encoded,
exang_encoded,
slope_encoded,
ca_encoded,
thal_encoded,
age_encoded,
trestbps_encoded,
chol_encoded,
thalach_encoded,
oldpeak_encoded,
]
)
x = tf.keras.layers.Dense(config["units"], activation=config["activation"])(
all_features
)
x = tf.keras.layers.Dropout(config["dropout_rate"])(x)
output = tf.keras.layers.Dense(1, activation="sigmoid")(x)
model = tf.keras.Model(all_inputs, output)
optimizer = tf.keras.optimizers.Adam(learning_rate=config["learning_rate"])
model.compile(optimizer, "binary_crossentropy", metrics=["accuracy"])
stopper_callback = TFKerasStopperCallback(
job,
monitor="val_accuracy",
mode="max"
)
history = model.fit(
train_ds,
epochs=100,
validation_data=val_ds,
verbose=0,
callbacks=[stopper_callback]
)
objective = history.history["val_accuracy"][-1]
metadata = {
"loss": history.history["loss"],
"val_loss": history.history["val_loss"],
"accuracy": history.history["accuracy"],
"val_accuracy": history.history["val_accuracy"],
}
metadata = {k:json.dumps(v) for k,v in metadata.items()}
metadata["budget"] = stopper_callback.budget
return {"objective": objective, "metadata": metadata}
The objective maximized by DeepHyper is the "objective" value returned by the run-function.
In this tutorial it corresponds to the validation accuracy of the last epoch of training which we retrieve in the History object returned by the model.fit(...) call.
...
objective = history.history["val_accuracy"][-1]
...
Using an objective like max(history.history['val_accuracy']) can have undesired side effects.
For example, it is possible that the training curves will overshoot a local maximum, resulting in a model without the capacity to flexibly adapt to new data in the future.
3.5. Define the Hyperparameter optimization problem#
Hyperparameter ranges are defined using the following syntax:
Discrete integer ranges are generated from a tuple
(lower: int, upper: int)Continuous prarameters are generated from a tuple
(lower: float, upper: float)Categorical or nonordinal hyperparameter ranges can be given as a list of possible values
[val1, val2, ...]
[16]:
from deephyper.problem import HpProblem
# Creation of an hyperparameter problem
problem = HpProblem()
# Discrete hyperparameter (sampled with uniform prior)
problem.add_hyperparameter((8, 128), "units", default_value=32)
# Categorical hyperparameter (sampled with uniform prior)
ACTIVATIONS = [
"elu", "gelu", "hard_sigmoid", "linear", "relu", "selu",
"sigmoid", "softplus", "softsign", "swish", "tanh",
]
problem.add_hyperparameter(ACTIVATIONS, "activation", default_value="relu")
# Real hyperparameter (sampled with uniform prior)
problem.add_hyperparameter((0.0, 0.6), "dropout_rate", default_value=0.5)
# Discrete and Real hyperparameters (sampled with log-uniform)
problem.add_hyperparameter((8, 256, "log-uniform"), "batch_size", default_value=32)
problem.add_hyperparameter((1e-5, 1e-2, "log-uniform"), "learning_rate", default_value=1e-3)
problem
[16]:
Configuration space object:
Hyperparameters:
activation, Type: Categorical, Choices: {elu, gelu, hard_sigmoid, linear, relu, selu, sigmoid, softplus, softsign, swish, tanh}, Default: relu
batch_size, Type: UniformInteger, Range: [8, 256], Default: 32, on log-scale
dropout_rate, Type: UniformFloat, Range: [0.0, 0.6], Default: 0.5
learning_rate, Type: UniformFloat, Range: [1e-05, 0.01], Default: 0.001, on log-scale
units, Type: UniformInteger, Range: [8, 128], Default: 32
3.6. Evaluate a default configuration#
We evaluate the performance of the default set of hyperparameters provided in the Keras tutorial.
[18]:
out = run(RunningJob(parameters=problem.default_configuration))
objective_default = out["objective"]
metadata_default = out["metadata"]
print(f"Accuracy of the default configuration is {objective_default:.3f}\n with a budget of {metadata_default['budget']}")
out
Accuracy of the default configuration is 0.787
with a budget of 100
[18]:
{'objective': 0.7868852615356445,
'metadata': {'timestamp_start': 1692627006.076231,
'timestamp_end': 1692627008.611656,
'loss': '[0.7388495802879333, 0.6523264050483704, 0.6074849367141724, 0.5875506401062012, 0.5609573125839233, 0.5364176630973816, 0.5154970288276672, 0.5150707364082336, 0.49714744091033936, 0.47235098481178284, 0.44334346055984497, 0.40525874495506287, 0.4218010902404785, 0.404602587223053, 0.40189820528030396, 0.38025644421577454, 0.3819867670536041, 0.3854610025882721, 0.41191190481185913, 0.3633726239204407, 0.38953328132629395, 0.38333550095558167, 0.37049752473831177, 0.3487849533557892, 0.32601648569107056, 0.37537238001823425, 0.34992167353630066, 0.3610842227935791, 0.3291627764701843, 0.3573709726333618, 0.3185168504714966, 0.3198896646499634, 0.342100590467453, 0.31612464785575867, 0.33958184719085693, 0.2965970039367676, 0.3082221746444702, 0.3110814690589905, 0.3165033161640167, 0.3095366954803467, 0.3058503568172455, 0.26944229006767273, 0.28905966877937317, 0.29246464371681213, 0.298763245344162, 0.29010289907455444, 0.3088240921497345, 0.2651433050632477, 0.28673067688941956, 0.28051823377609253, 0.30437788367271423, 0.27532726526260376, 0.27114972472190857, 0.2815909683704376, 0.26282840967178345, 0.2893137037754059, 0.2620639204978943, 0.2733112573623657, 0.29566553235054016, 0.24813897907733917, 0.2784141004085541, 0.2645460367202759, 0.2866308391094208, 0.2698310613632202, 0.2550477385520935, 0.2571200430393219, 0.2692863345146179, 0.28535759449005127, 0.25309813022613525, 0.23560240864753723, 0.2546529769897461, 0.2909449338912964, 0.27611395716667175, 0.2572629451751709, 0.25273746252059937, 0.26408591866493225, 0.2512419521808624, 0.25369662046432495, 0.2681562900543213, 0.26099127531051636, 0.26887956261634827, 0.27868539094924927, 0.25104275345802307, 0.24246439337730408, 0.2736146152019501, 0.229806587100029, 0.23607467114925385, 0.25247693061828613, 0.26732784509658813, 0.23494768142700195, 0.24175147712230682, 0.24835185706615448, 0.24178683757781982, 0.23670029640197754, 0.25046640634536743, 0.2326313853263855, 0.252770334482193, 0.20456381142139435, 0.22638487815856934, 0.23603281378746033]',
'val_loss': '[0.6194877624511719, 0.5722625255584717, 0.5385775566101074, 0.508735716342926, 0.4839463233947754, 0.4639243483543396, 0.4494287371635437, 0.43661004304885864, 0.4258253872394562, 0.4169422388076782, 0.4105747938156128, 0.4043523371219635, 0.3982822299003601, 0.393393874168396, 0.3889952003955841, 0.38584354519844055, 0.38407716155052185, 0.3818555176258087, 0.3788350224494934, 0.3772242069244385, 0.3753066062927246, 0.37455886602401733, 0.37446901202201843, 0.3741632103919983, 0.3731308579444885, 0.3719276189804077, 0.371856689453125, 0.3722780644893646, 0.37168246507644653, 0.37138059735298157, 0.37127938866615295, 0.371003121137619, 0.3717569410800934, 0.3721306622028351, 0.37286439538002014, 0.3737015724182129, 0.3748771846294403, 0.37533822655677795, 0.3756699562072754, 0.37536323070526123, 0.37565532326698303, 0.3775019943714142, 0.37845736742019653, 0.3793482482433319, 0.37970390915870667, 0.38008853793144226, 0.38097918033599854, 0.3820502758026123, 0.38251516222953796, 0.38319170475006104, 0.3819979727268219, 0.3817276656627655, 0.38192903995513916, 0.38186657428741455, 0.38266661763191223, 0.3833865225315094, 0.38367798924446106, 0.38322150707244873, 0.3829233646392822, 0.3829481899738312, 0.3825083374977112, 0.383163720369339, 0.38400524854660034, 0.3840462863445282, 0.3839638829231262, 0.38363203406333923, 0.3847125172615051, 0.3835242986679077, 0.3827455937862396, 0.38354116678237915, 0.38440680503845215, 0.3843563199043274, 0.3848268389701843, 0.38419896364212036, 0.38506948947906494, 0.385724812746048, 0.38643878698349, 0.38729530572891235, 0.3885875642299652, 0.3890146315097809, 0.39021605253219604, 0.39056646823883057, 0.39105290174484253, 0.391281396150589, 0.3917790353298187, 0.39285603165626526, 0.39422619342803955, 0.3948151469230652, 0.39457252621650696, 0.3959348797798157, 0.39613062143325806, 0.39701947569847107, 0.3969540297985077, 0.39677679538726807, 0.3973367512226105, 0.39705222845077515, 0.39696934819221497, 0.39737534523010254, 0.39815035462379456, 0.3987182378768921]',
'accuracy': '[0.5454545617103577, 0.6570248007774353, 0.6983470916748047, 0.6776859760284424, 0.7272727489471436, 0.7479338645935059, 0.7561983466148376, 0.7396694421768188, 0.7355371713638306, 0.7561983466148376, 0.7644628286361694, 0.8429751992225647, 0.8057851195335388, 0.8223140239715576, 0.8099173307418823, 0.8471074104309082, 0.8181818127632141, 0.8388429880142212, 0.7851239442825317, 0.8471074104309082, 0.8223140239715576, 0.8264462947845459, 0.8429751992225647, 0.8512396812438965, 0.8760330677032471, 0.8264462947845459, 0.8636363744735718, 0.8223140239715576, 0.8760330677032471, 0.8429751992225647, 0.85537189245224, 0.85537189245224, 0.8429751992225647, 0.8677685856819153, 0.8388429880142212, 0.8925619721412659, 0.8512396812438965, 0.8636363744735718, 0.8636363744735718, 0.8677685856819153, 0.8719007968902588, 0.8925619721412659, 0.8925619721412659, 0.8719007968902588, 0.8760330677032471, 0.85537189245224, 0.8760330677032471, 0.8966942429542542, 0.8801652789115906, 0.8842975497245789, 0.8595041036605835, 0.8884297609329224, 0.8966942429542542, 0.8842975497245789, 0.8677685856819153, 0.8677685856819153, 0.8842975497245789, 0.8636363744735718, 0.8801652789115906, 0.9090909361839294, 0.8719007968902588, 0.8760330677032471, 0.8760330677032471, 0.8719007968902588, 0.9008264541625977, 0.9173553586006165, 0.8966942429542542, 0.8842975497245789, 0.8884297609329224, 0.8925619721412659, 0.913223147392273, 0.8636363744735718, 0.8801652789115906, 0.8925619721412659, 0.9049586653709412, 0.8842975497245789, 0.8842975497245789, 0.9008264541625977, 0.8801652789115906, 0.8842975497245789, 0.8966942429542542, 0.8760330677032471, 0.9090909361839294, 0.8842975497245789, 0.8677685856819153, 0.9090909361839294, 0.9090909361839294, 0.8966942429542542, 0.8760330677032471, 0.913223147392273, 0.9008264541625977, 0.913223147392273, 0.8966942429542542, 0.9008264541625977, 0.8966942429542542, 0.8966942429542542, 0.8925619721412659, 0.913223147392273, 0.9008264541625977, 0.9049586653709412]',
'val_accuracy': '[0.6393442749977112, 0.7049180269241333, 0.7213114500045776, 0.7213114500045776, 0.7213114500045776, 0.7377049326896667, 0.7704917788505554, 0.7704917788505554, 0.7868852615356445, 0.8196721076965332, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8360655903816223, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.8032786846160889, 0.7868852615356445, 0.7868852615356445, 0.7868852615356445, 0.7868852615356445, 0.7868852615356445, 0.7868852615356445, 0.7868852615356445]',
'budget': 100}}
3.7. Execute Multi-Fidelity Bayesian Optimization#
We create the CBO using the problem and run-function defined above. When directly passing the run-function to the search it is wrapped inside a deephyper.evaluator.SerialEvaluator. Then, we also import the deephyper.stopper.LCModelStopper.
[19]:
from deephyper.search.hps import CBO
from deephyper.stopper import LCModelStopper
[20]:
# Instanciate the search with the problem and the evaluator that we created before
stopper = LCModelStopper(min_steps=1, max_steps=100)
search = CBO(
problem,
run,
initial_points=[problem.default_configuration],
stopper=stopper,
verbose=1,
)
Note
All DeepHyper’s search algorithm have two stopping criteria:
max_evals (int): Defines the maximum number of evaluations that we want to perform. Default to -1 for an infinite number.timeout (int): Defines a time budget (in seconds) before stopping the search. Default to None for an infinite time budget.
[21]:
results = search.search(max_evals=30)
The returned results is a Pandas Dataframe where columns starting by "p:" are hyperparameters, columns starting by "m:" are additional metadata (from the user or from the Evaluator) as well as the objective value and the job_id:
job_idis a unique identifier corresponding to the order of creation of tasks.objectiveis the value returned by the run-function.m:timestamp_submitis the time (in seconds) when the task was created by the evaluator since the creation of the evaluator.m:timestamp_gatheris the time (in seconds) when the task was received after finishing by the evaluator since the creation of the evaluator.m:timestamp_startis the time (in seconds) when the task started to run.m:timestamp_endis the time (in seconds) when task finished to run.m:budgetis the consumed number of epoch for each evaluation.
[22]:
results
[22]:
| p:activation | p:batch_size | p:dropout_rate | p:learning_rate | p:units | objective | job_id | m:timestamp_submit | m:timestamp_gather | m:timestamp_start | m:timestamp_end | m:loss | m:val_loss | m:accuracy | m:val_accuracy | m:budget | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | relu | 32 | 0.500000 | 0.001000 | 32 | 0.803279 | 0 | 3.554752 | 7.302983 | 1.692627e+09 | 1.692627e+09 | [0.6227220296859741, 0.5570479035377502, 0.538... | [0.5288254618644714, 0.4989699125289917, 0.475... | [0.6487603187561035, 0.7438016533851624, 0.756... | [0.7868852615356445, 0.8032786846160889, 0.819... | 35 |
| 1 | linear | 9 | 0.147090 | 0.001889 | 49 | 0.803279 | 1 | 7.347784 | 10.729823 | 1.692627e+09 | 1.692627e+09 | [0.49330684542655945, 0.3671776056289673, 0.30... | [0.3687109649181366, 0.3877825140953064, 0.386... | [0.7479338645935059, 0.8264462947845459, 0.851... | [0.8032786846160889, 0.868852436542511, 0.8524... | 27 |
| 2 | softsign | 12 | 0.499104 | 0.000029 | 100 | 0.786885 | 2 | 10.749194 | 14.626382 | 1.692627e+09 | 1.692627e+09 | [0.710996150970459, 0.7085673213005066, 0.7007... | [0.6798619031906128, 0.6712697148323059, 0.663... | [0.5289255976676941, 0.5495867729187012, 0.561... | [0.5409836173057556, 0.5409836173057556, 0.557... | 59 |
| 3 | softsign | 27 | 0.582597 | 0.000215 | 97 | 0.868852 | 3 | 14.645453 | 18.470026 | 1.692627e+09 | 1.692627e+09 | [0.6582441329956055, 0.6144227385520935, 0.614... | [0.6063965559005737, 0.5792577862739563, 0.555... | [0.6157024502754211, 0.6528925895690918, 0.648... | [0.7213114500045776, 0.7540983557701111, 0.737... | 64 |
| 4 | selu | 28 | 0.469018 | 0.000618 | 110 | 0.786885 | 4 | 18.490789 | 21.121490 | 1.692627e+09 | 1.692627e+09 | [0.6250562071800232, 0.5189632177352905, 0.483... | [0.49002861976623535, 0.423252135515213, 0.386... | [0.6818181872367859, 0.7231404781341553, 0.731... | [0.7704917788505554, 0.8196721076965332, 0.786... | 4 |
| 5 | linear | 15 | 0.289261 | 0.000777 | 68 | 0.819672 | 5 | 21.140275 | 23.720370 | 1.692627e+09 | 1.692627e+09 | [0.6295762062072754, 0.4781874716281891, 0.421... | [0.5124895572662354, 0.433324933052063, 0.4010... | [0.6735537052154541, 0.7603305578231812, 0.801... | [0.8032786846160889, 0.7868852615356445, 0.803... | 4 |
| 6 | elu | 133 | 0.007165 | 0.000024 | 88 | 0.688525 | 6 | 23.738940 | 26.728599 | 1.692627e+09 | 1.692627e+09 | [0.6447474956512451, 0.6408497095108032, 0.641... | [0.597851037979126, 0.5967557430267334, 0.5956... | [0.6280992031097412, 0.6322314143180847, 0.640... | [0.688524603843689, 0.688524603843689, 0.68852... | 4 |
| 7 | elu | 184 | 0.365660 | 0.000276 | 126 | 0.704918 | 7 | 26.748085 | 29.293730 | 1.692627e+09 | 1.692627e+09 | [0.6677700281143188, 0.6242449879646301, 0.632... | [0.6279993057250977, 0.612653374671936, 0.5987... | [0.6239669322967529, 0.6652892827987671, 0.673... | [0.7049180269241333, 0.7213114500045776, 0.721... | 4 |
| 8 | linear | 27 | 0.410357 | 0.003974 | 10 | 0.819672 | 8 | 29.312796 | 32.318316 | 1.692627e+09 | 1.692627e+09 | [0.6348783373832703, 0.4910481572151184, 0.433... | [0.5030055046081543, 0.4379017949104309, 0.406... | [0.7066115736961365, 0.7438016533851624, 0.801... | [0.7540983557701111, 0.8032786846160889, 0.803... | 31 |
| 9 | gelu | 37 | 0.586930 | 0.001828 | 94 | 0.786885 | 9 | 32.583841 | 35.622722 | 1.692627e+09 | 1.692627e+09 | [0.646159291267395, 0.5308106541633606, 0.4458... | [0.5199227333068848, 0.44885024428367615, 0.40... | [0.6363636255264282, 0.7479338645935059, 0.809... | [0.8196721076965332, 0.7868852615356445, 0.786... | 35 |
| 10 | softsign | 15 | 0.580355 | 0.000195 | 88 | 0.426230 | 10 | 35.721770 | 37.368073 | 1.692627e+09 | 1.692627e+09 | [0.7734954953193665] | [0.7477120161056519] | [0.41735535860061646] | [0.4262295067310333] | 1 |
| 11 | swish | 27 | 0.599008 | 0.000148 | 80 | 0.245902 | 11 | 37.469103 | 38.974784 | 1.692627e+09 | 1.692627e+09 | [0.828150749206543] | [0.810135006904602] | [0.3636363744735718] | [0.24590164422988892] | 1 |
| 12 | softplus | 11 | 0.590109 | 0.000299 | 97 | 0.770492 | 12 | 39.081071 | 41.960308 | 1.692627e+09 | 1.692627e+09 | [0.8678354024887085, 0.7065883874893188, 0.700... | [0.6125381588935852, 0.5351727604866028, 0.495... | [0.5206611752510071, 0.5909090638160706, 0.669... | [0.7049180269241333, 0.7704917788505554, 0.770... | 4 |
| 13 | softsign | 24 | 0.568922 | 0.000112 | 122 | 0.803279 | 13 | 42.066191 | 45.404559 | 1.692627e+09 | 1.692627e+09 | [0.724600076675415, 0.7176037430763245, 0.6875... | [0.6987729072570801, 0.674211859703064, 0.6525... | [0.4958677589893341, 0.5454545617103577, 0.607... | [0.5573770403862, 0.6065573692321777, 0.655737... | 40 |
| 14 | softsign | 29 | 0.578839 | 0.000159 | 105 | 0.803279 | 14 | 45.507679 | 48.744906 | 1.692627e+09 | 1.692627e+09 | [0.7335056662559509, 0.7066584229469299, 0.688... | [0.7332508563995361, 0.7050181031227112, 0.679... | [0.46694216132164, 0.5289255976676941, 0.52066... | [0.44262295961380005, 0.49180328845977783, 0.5... | 51 |
| 15 | linear | 16 | 0.287004 | 0.000726 | 69 | 0.786885 | 15 | 48.853081 | 52.410750 | 1.692627e+09 | 1.692627e+09 | [0.6595832109451294, 0.5204204320907593, 0.485... | [0.48184749484062195, 0.4187839925289154, 0.38... | [0.64462810754776, 0.7148760557174683, 0.74793... | [0.8032786846160889, 0.8032786846160889, 0.819... | 37 |
| 16 | tanh | 27 | 0.433537 | 0.005760 | 24 | 0.786885 | 16 | 52.515180 | 55.492876 | 1.692627e+09 | 1.692627e+09 | [0.4885702431201935, 0.4026663899421692, 0.338... | [0.3990103304386139, 0.3842548429965973, 0.395... | [0.7644628286361694, 0.8016529083251953, 0.847... | [0.8196721076965332, 0.8032786846160889, 0.852... | 29 |
| 17 | softsign | 32 | 0.597483 | 0.000243 | 8 | 0.803279 | 17 | 55.600845 | 59.004269 | 1.692627e+09 | 1.692627e+09 | [0.8090429306030273, 0.7903764247894287, 0.808... | [0.7881447076797485, 0.7788082361221313, 0.769... | [0.4586776793003082, 0.44628098607063293, 0.45... | [0.31147539615631104, 0.31147539615631104, 0.3... | 63 |
| 18 | swish | 24 | 0.584958 | 0.000213 | 111 | 0.852459 | 18 | 59.111170 | 62.916621 | 1.692627e+09 | 1.692627e+09 | [0.6998273134231567, 0.6901867985725403, 0.633... | [0.6759735941886902, 0.6463225483894348, 0.621... | [0.5289255976676941, 0.56611567735672, 0.65289... | [0.6065573692321777, 0.6721311211585999, 0.672... | 36 |
| 19 | swish | 25 | 0.598112 | 0.000129 | 124 | 0.409836 | 19 | 63.025823 | 65.628007 | 1.692627e+09 | 1.692627e+09 | [0.7799810171127319, 0.7728349566459656, 0.743... | [0.7869507670402527, 0.7617835998535156, 0.738... | [0.39256197214126587, 0.42148759961128235, 0.4... | [0.26229506731033325, 0.3442623019218445, 0.37... | 4 |
| 20 | swish | 24 | 0.503962 | 0.000188 | 108 | 0.852459 | 20 | 65.737362 | 69.012517 | 1.692627e+09 | 1.692627e+09 | [0.7826627492904663, 0.7401067018508911, 0.716... | [0.7268974184989929, 0.6923832893371582, 0.661... | [0.40495866537094116, 0.4710743725299835, 0.51... | [0.4098360538482666, 0.5409836173057556, 0.672... | 52 |
| 21 | swish | 23 | 0.508027 | 0.000195 | 121 | 0.786885 | 21 | 69.122440 | 72.220513 | 1.692627e+09 | 1.692627e+09 | [0.6466206312179565, 0.6104539036750793, 0.596... | [0.6054739952087402, 0.5772570967674255, 0.553... | [0.6363636255264282, 0.7355371713638306, 0.739... | [0.688524603843689, 0.7704917788505554, 0.7704... | 16 |
| 22 | swish | 21 | 0.599638 | 0.000220 | 115 | 0.803279 | 22 | 72.331612 | 75.464572 | 1.692627e+09 | 1.692627e+09 | [0.7254757285118103, 0.6856257915496826, 0.656... | [0.7080947756767273, 0.6708484292030334, 0.636... | [0.4834710657596588, 0.5289255976676941, 0.628... | [0.5081967115402222, 0.6393442749977112, 0.737... | 36 |
| 23 | swish | 24 | 0.559085 | 0.000214 | 88 | 0.721311 | 23 | 75.574948 | 78.101354 | 1.692627e+09 | 1.692627e+09 | [0.7135123610496521, 0.6844885349273682, 0.662... | [0.6889106631278992, 0.6591018438339233, 0.631... | [0.4834710657596588, 0.5619834661483765, 0.595... | [0.5081967115402222, 0.6229507923126221, 0.704... | 4 |
| 24 | softplus | 26 | 0.576747 | 0.000199 | 102 | 0.803279 | 24 | 78.210997 | 81.422945 | 1.692627e+09 | 1.692627e+09 | [0.8818848729133606, 0.8496137857437134, 0.756... | [0.7038170695304871, 0.6505393385887146, 0.610... | [0.4793388545513153, 0.4752066135406494, 0.537... | [0.4098360538482666, 0.8360655903816223, 0.819... | 27 |
| 25 | swish | 24 | 0.567181 | 0.000209 | 107 | 0.754098 | 25 | 81.533879 | 84.056534 | 1.692627e+09 | 1.692627e+09 | [0.7189084887504578, 0.7079837918281555, 0.677... | [0.6937562227249146, 0.6694052219390869, 0.646... | [0.5371900796890259, 0.557851254940033, 0.5785... | [0.5901639461517334, 0.6557376980781555, 0.721... | 4 |
| 26 | tanh | 24 | 0.503059 | 0.000118 | 100 | 0.754098 | 26 | 84.166216 | 86.679132 | 1.692627e+09 | 1.692627e+09 | [0.6868227124214172, 0.6927969455718994, 0.650... | [0.6453925967216492, 0.6199279427528381, 0.596... | [0.5826446413993835, 0.5785123705863953, 0.648... | [0.6721311211585999, 0.688524603843689, 0.7377... | 4 |
| 27 | softsign | 27 | 0.552740 | 0.000288 | 101 | 0.836066 | 27 | 86.789922 | 90.000142 | 1.692627e+09 | 1.692627e+09 | [0.6240310072898865, 0.6154924035072327, 0.591... | [0.5968618392944336, 0.5632079243659973, 0.535... | [0.6652892827987671, 0.6363636255264282, 0.739... | [0.8032786846160889, 0.8360655903816223, 0.819... | 27 |
| 28 | softsign | 26 | 0.585004 | 0.000215 | 104 | 0.836066 | 28 | 90.113099 | 93.519698 | 1.692627e+09 | 1.692627e+09 | [0.6899656057357788, 0.6779984831809998, 0.646... | [0.677489161491394, 0.6455464363098145, 0.6153... | [0.5619834661483765, 0.5743801593780518, 0.644... | [0.5573770403862, 0.6065573692321777, 0.639344... | 64 |
| 29 | softsign | 19 | 0.582967 | 0.000434 | 96 | 0.803279 | 29 | 93.630995 | 96.207705 | 1.692627e+09 | 1.692627e+09 | [0.7093287110328674, 0.5999704003334045, 0.584... | [0.6647931933403015, 0.5841431021690369, 0.525... | [0.5289255976676941, 0.6983470916748047, 0.706... | [0.5573770403862, 0.7540983557701111, 0.803278... | 4 |
Now that the search is over, let us print the best configuration found during this run.
[24]:
i_max = results.objective.argmax()
best_job = results.iloc[i_max].to_dict()
print(f"The default configuration has an accuracy of {objective_default:.3f}. \n"
f"The best configuration found by DeepHyper has an accuracy {results['objective'].iloc[i_max]:.3f}, \n"
f"discovered after {results['m:timestamp_gather'].iloc[i_max]:.2f} secondes of search.\n")
best_job
The default configuration has an accuracy of 0.787.
The best configuration found by DeepHyper has an accuracy 0.869,
discovered after 18.47 secondes of search.
[24]:
{'p:activation': 'softsign',
'p:batch_size': 27,
'p:dropout_rate': 0.5825972321970286,
'p:learning_rate': 0.0002146492013936,
'p:units': 97,
'objective': 0.868852436542511,
'job_id': 3,
'm:timestamp_submit': 14.645452976226808,
'm:timestamp_gather': 18.47002601623535,
'm:timestamp_start': 1692627056.0797062,
'm:timestamp_end': 1692627059.903903,
'm:loss': '[0.6582441329956055, 0.6144227385520935, 0.6145278215408325, 0.6029292941093445, 0.5701202154159546, 0.5590323209762573, 0.5266819000244141, 0.5313710570335388, 0.5190641283988953, 0.48551449179649353, 0.4518640339374542, 0.4618057608604431, 0.47630706429481506, 0.4841085374355316, 0.46425509452819824, 0.46001386642456055, 0.4311169981956482, 0.42034876346588135, 0.4447265863418579, 0.4271446466445923, 0.41852933168411255, 0.42826342582702637, 0.4135468304157257, 0.40737172961235046, 0.3894239068031311, 0.38594695925712585, 0.4143550395965576, 0.3991055190563202, 0.39989709854125977, 0.3991136848926544, 0.3789837062358856, 0.3853186070919037, 0.37715306878089905, 0.37205013632774353, 0.37237340211868286, 0.3673132061958313, 0.3666028082370758, 0.35598233342170715, 0.3553876280784607, 0.3808722496032715, 0.35543930530548096, 0.34617236256599426, 0.35386309027671814, 0.37097516655921936, 0.3688899576663971, 0.35417208075523376, 0.35026198625564575, 0.3427666425704956, 0.346967488527298, 0.3532065153121948, 0.33742740750312805, 0.3545960783958435, 0.3325014114379883, 0.33512216806411743, 0.32153061032295227, 0.3290161192417145, 0.3484468460083008, 0.34243884682655334, 0.33464089035987854, 0.32899194955825806, 0.32888177037239075, 0.3334735631942749, 0.3368818759918213, 0.3451095521450043]',
'm:val_loss': '[0.6063965559005737, 0.5792577862739563, 0.5556067824363708, 0.5347539782524109, 0.5161513090133667, 0.5006381869316101, 0.4881114661693573, 0.47605815529823303, 0.4642772376537323, 0.45479875802993774, 0.4466439485549927, 0.43913522362709045, 0.43216830492019653, 0.4264807105064392, 0.42094600200653076, 0.41611552238464355, 0.4121261537075043, 0.4083685278892517, 0.4054298996925354, 0.40238967537879944, 0.3995138108730316, 0.39638280868530273, 0.39376404881477356, 0.3915865421295166, 0.3895185589790344, 0.38762181997299194, 0.38626304268836975, 0.3853980302810669, 0.3846575915813446, 0.38337844610214233, 0.38249704241752625, 0.38157397508621216, 0.38086169958114624, 0.3803839385509491, 0.3804793655872345, 0.3803507685661316, 0.3803969919681549, 0.379818856716156, 0.3797812759876251, 0.37954601645469666, 0.3791370987892151, 0.3784518837928772, 0.3781093955039978, 0.377916544675827, 0.37754306197166443, 0.3776501715183258, 0.37767040729522705, 0.3779224455356598, 0.3777530789375305, 0.37799403071403503, 0.37827208638191223, 0.3791006803512573, 0.3788507282733917, 0.37848344445228577, 0.3786301016807556, 0.3790893256664276, 0.37959209084510803, 0.38035571575164795, 0.3806765675544739, 0.38088637590408325, 0.38094907999038696, 0.3814001977443695, 0.3820967972278595, 0.3824552893638611]',
'm:accuracy': '[0.6157024502754211, 0.6528925895690918, 0.6487603187561035, 0.6735537052154541, 0.71074378490448, 0.7685950398445129, 0.7561983466148376, 0.7520661354064941, 0.7438016533851624, 0.7727272510528564, 0.8099173307418823, 0.7851239442825317, 0.797520637512207, 0.7933884263038635, 0.7851239442825317, 0.78925621509552, 0.8140496015548706, 0.8181818127632141, 0.8140496015548706, 0.8057851195335388, 0.8347107172012329, 0.8264462947845459, 0.8181818127632141, 0.8264462947845459, 0.8347107172012329, 0.8223140239715576, 0.8305785059928894, 0.8181818127632141, 0.8429751992225647, 0.8264462947845459, 0.8305785059928894, 0.8223140239715576, 0.8471074104309082, 0.8512396812438965, 0.8429751992225647, 0.8305785059928894, 0.8429751992225647, 0.8512396812438965, 0.8595041036605835, 0.8181818127632141, 0.8388429880142212, 0.85537189245224, 0.8264462947845459, 0.8181818127632141, 0.8388429880142212, 0.8471074104309082, 0.8347107172012329, 0.8512396812438965, 0.8471074104309082, 0.8471074104309082, 0.85537189245224, 0.8512396812438965, 0.8760330677032471, 0.8388429880142212, 0.8760330677032471, 0.8471074104309082, 0.8347107172012329, 0.8471074104309082, 0.85537189245224, 0.8677685856819153, 0.85537189245224, 0.85537189245224, 0.8471074104309082, 0.8429751992225647]',
'm:val_accuracy': '[0.7213114500045776, 0.7540983557701111, 0.7377049326896667, 0.7540983557701111, 0.7868852615356445, 0.7868852615356445, 0.7868852615356445, 0.7868852615356445, 0.8196721076965332, 0.8196721076965332, 0.8196721076965332, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8360655903816223, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.8524590134620667, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511, 0.868852436542511]',
'm:budget': 64}
[25]:
import matplotlib.pyplot as plt
plt.figure()
plt.plot(json.loads(metadata_default["val_accuracy"]), color="skyblue", label="Default (val)")
plt.plot(json.loads(metadata_default["accuracy"]), color="skyblue", linestyle="--", label="Default (train)")
plt.plot(json.loads(best_job["m:val_accuracy"]), color="coral", linewidth=2, label="Best Job(val)")
plt.plot(json.loads(best_job["m:accuracy"]), color="coral", linestyle="--", linewidth=2, label="Best Job (train)")
plt.legend()
plt.xlim(0,50)
plt.ylim(0.5, 0.9)
plt.grid()
plt.show()
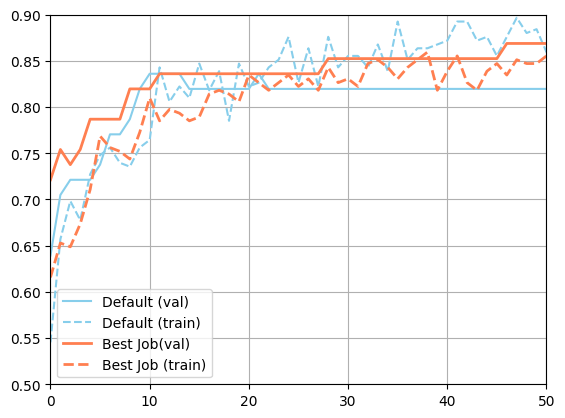
We can observe an improvement of more than 3% in accuracy. We can retrieve the corresponding hyperparameter configuration with the number of epochs used for this evaluation (32).