
Note
Go to the end to download the full example code.
Profile the Worker Utilization#
Author(s): Romain Egele.
In this example, you will learn how to profile the activity of workers during a search.
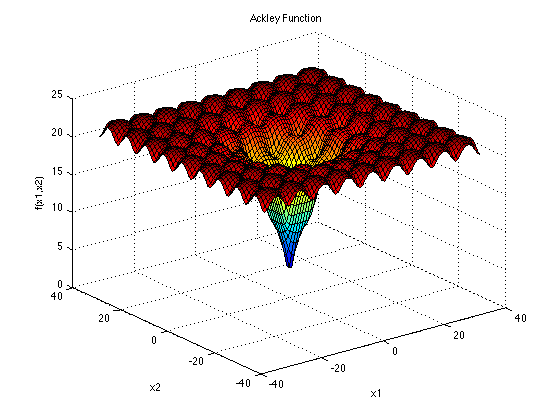
We start by defining an artificial black-box run-function by using the Ackley function:
Code (Import statements)
import time
import matplotlib.pyplot as plt
import numpy as np
from deephyper.analysis import figure_size
from deephyper.analysis.hpo import (
plot_search_trajectory_single_objective_hpo,
plot_worker_utilization,
)
from deephyper.evaluator import Evaluator, profile
from deephyper.evaluator.callback import TqdmCallback
from deephyper.hpo import CBO, HpProblem
We define the Ackley function:
Code (Ackley function)
We will use the time.sleep function to simulate a budget of 2 secondes of execution in average
which helps illustrate the advantage of parallel evaluations. The @profile decorator is useful
to collect starting/ending time of the run-function execution which help us know exactly when
we are inside the black-box. This decorator is necessary when profiling the worker utilization. When
using this decorator, the run-function will return a dictionnary with 2 new keys "timestamp_start"
and "timestamp_end".
@profile
def run_ackley(config, sleep_loc=2, sleep_scale=0.5):
# to simulate the computation of an expensive black-box
if sleep_loc > 0:
t_sleep = np.random.normal(loc=sleep_loc, scale=sleep_scale)
t_sleep = max(t_sleep, 0)
time.sleep(t_sleep)
x = np.array([config[k] for k in config if "x" in k])
x = np.asarray_chkfinite(x) # ValueError if any NaN or Inf
return -ackley(x) # maximisation is performed
Then we define the variable(s) we want to optimize. For this problem we
optimize Ackley in a 2-dimensional search space, the true minimul is
located at (0, 0).
Configuration space object:
Hyperparameters:
x0, Type: UniformFloat, Range: [-32.768, 32.768], Default: 0.0
x1, Type: UniformFloat, Range: [-32.768, 32.768], Default: 0.0
- Then we define a parallel search.
As the
run-function is defined in the same module we use the “loky” backend
that serialize by value.
def execute_search(timeout, num_workers):
evaluator = Evaluator.create(
run_ackley,
method="loky",
method_kwargs={
"num_workers": num_workers,
"callbacks": [TqdmCallback()],
},
)
search = CBO(
problem,
multi_point_strategy="qUCBd",
random_state=42,
)
results = search.search(evaluator, timeout=timeout)
return results
if __name__ == "__main__":
timeout = 20
num_workers = 4
results = execute_search(timeout, num_workers)
0it [00:00, ?it/s]
1it [00:00, 7530.17it/s, failures=0, objective=-19.8]
2it [00:01, 2.00it/s, failures=0, objective=-19.8]
2it [00:01, 2.00it/s, failures=0, objective=-19.8]
3it [00:01, 2.00it/s, failures=0, objective=-19.8]
4it [00:01, 2.41it/s, failures=0, objective=-19.8]
4it [00:01, 2.41it/s, failures=0, objective=-19.8]
5it [00:01, 2.99it/s, failures=0, objective=-19.8]
5it [00:01, 2.99it/s, failures=0, objective=-19.8]
6it [00:02, 1.78it/s, failures=0, objective=-19.8]
6it [00:02, 1.78it/s, failures=0, objective=-19.8]
7it [00:03, 1.99it/s, failures=0, objective=-19.8]
7it [00:03, 1.99it/s, failures=0, objective=-15.4]
8it [00:03, 2.26it/s, failures=0, objective=-15.4]
8it [00:03, 2.26it/s, failures=0, objective=-15.4]
9it [00:04, 1.84it/s, failures=0, objective=-15.4]
9it [00:04, 1.84it/s, failures=0, objective=-15.4]
10it [00:05, 1.42it/s, failures=0, objective=-15.4]
10it [00:05, 1.42it/s, failures=0, objective=-15.4]
11it [00:05, 1.58it/s, failures=0, objective=-15.4]
11it [00:05, 1.58it/s, failures=0, objective=-15.4]
12it [00:06, 1.82it/s, failures=0, objective=-15.4]
12it [00:06, 1.82it/s, failures=0, objective=-14.2]
13it [00:07, 1.37it/s, failures=0, objective=-14.2]
13it [00:07, 1.37it/s, failures=0, objective=-14.2]
14it [00:07, 1.68it/s, failures=0, objective=-14.2]
14it [00:07, 1.68it/s, failures=0, objective=-14.2]
15it [00:08, 1.85it/s, failures=0, objective=-14.2]
15it [00:08, 1.85it/s, failures=0, objective=-14.2]
16it [00:08, 1.83it/s, failures=0, objective=-14.2]
16it [00:08, 1.83it/s, failures=0, objective=-10.8]
17it [00:09, 1.85it/s, failures=0, objective=-10.8]
17it [00:09, 1.85it/s, failures=0, objective=-10.8]
18it [00:09, 2.20it/s, failures=0, objective=-10.8]
18it [00:09, 2.20it/s, failures=0, objective=-10.8]
19it [00:10, 1.43it/s, failures=0, objective=-10.8]
19it [00:10, 1.43it/s, failures=0, objective=-10.8]
20it [00:10, 1.80it/s, failures=0, objective=-10.8]
20it [00:10, 1.80it/s, failures=0, objective=-6.95]
21it [00:12, 1.36it/s, failures=0, objective=-6.95]
21it [00:12, 1.36it/s, failures=0, objective=-5.75]
22it [00:12, 1.71it/s, failures=0, objective=-5.75]
22it [00:12, 1.71it/s, failures=0, objective=-5.75]
23it [00:12, 1.99it/s, failures=0, objective=-5.75]
23it [00:12, 1.99it/s, failures=0, objective=-5.75]
24it [00:13, 2.05it/s, failures=0, objective=-5.75]
24it [00:13, 2.05it/s, failures=0, objective=-5.75]
25it [00:14, 1.33it/s, failures=0, objective=-5.75]
25it [00:14, 1.33it/s, failures=0, objective=-5.75]
26it [00:15, 1.43it/s, failures=0, objective=-5.75]
26it [00:15, 1.43it/s, failures=0, objective=-5.75]
27it [00:15, 1.65it/s, failures=0, objective=-5.75]
27it [00:15, 1.65it/s, failures=0, objective=-3.36]
28it [00:15, 1.85it/s, failures=0, objective=-3.36]
28it [00:15, 1.85it/s, failures=0, objective=-3.36]
29it [00:17, 1.21it/s, failures=0, objective=-3.36]
29it [00:17, 1.21it/s, failures=0, objective=-3.36]
30it [00:17, 1.49it/s, failures=0, objective=-3.36]
30it [00:17, 1.49it/s, failures=0, objective=-3.36]
31it [00:17, 1.49it/s, failures=0, objective=-3.36]
32it [00:17, 1.49it/s, failures=0, objective=-3.36]
33it [00:18, 1.88it/s, failures=0, objective=-3.36]
33it [00:18, 1.88it/s, failures=0, objective=-3.36]
34it [00:20, 1.52it/s, failures=0, objective=-3.36]
34it [00:20, 1.52it/s, failures=0, objective=-2.07]
35it [00:20, 1.52it/s, failures=0, objective=-0.727]
36it [00:20, 1.52it/s, failures=0, objective=-0.727]
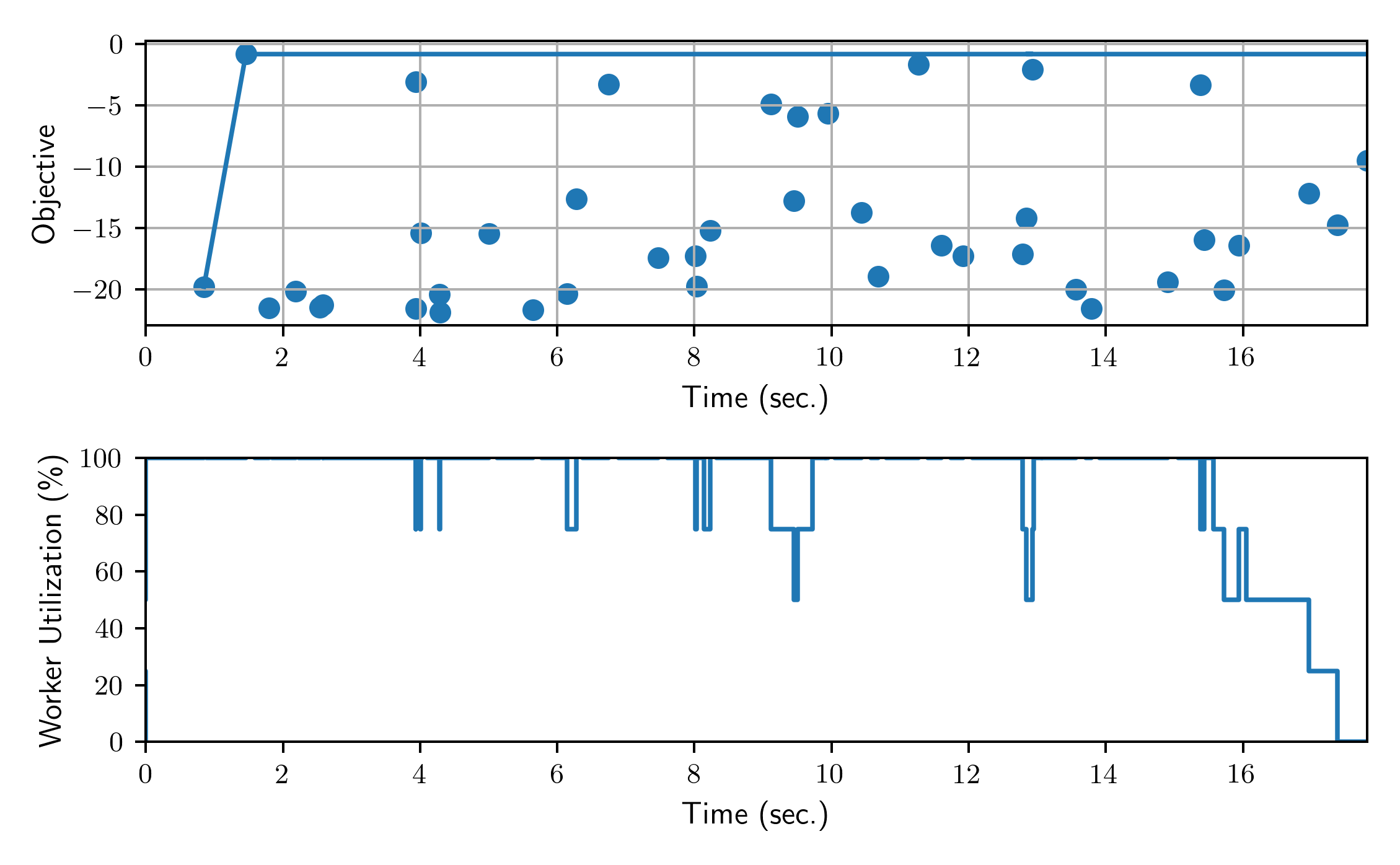
Finally, we plot the results from the collected DataFrame.
Code (Plot search trajectory an workers utilization)
if __name__ == "__main__":
t0 = results["m:timestamp_start"].iloc[0]
results["m:timestamp_start"] = results["m:timestamp_start"] - t0
results["m:timestamp_end"] = results["m:timestamp_end"] - t0
tmax = results["m:timestamp_end"].max()
fig, axes = plt.subplots(
nrows=2,
ncols=1,
sharex=True,
figsize=figure_size(width=600),
tight_layout=True,
)
_ = plot_search_trajectory_single_objective_hpo(
results, mode="min", x_units="seconds", ax=axes[0],
)
_ = plot_worker_utilization(
results, num_workers=num_workers, profile_type="start/end", ax=axes[1],
)
Total running time of the script: (0 minutes 23.347 seconds)